
Организации ежедневно обрабатывают миллионы документов: страховые претензии, счета-фактуры, юридические контракты и медицинские записи. Традиционные решения оптического распознавания символов (OCR) извлекают текст, но не понимают контекст, связи и смысл, заложенные в документе. Это ограничение создаёт узкие места, требующие ручного вмешательства, увеличивая время обработки и затраты, а также повышая риск ошибок.
Amazon Bedrock Data Automation (BDA) решает эту проблему, предоставляя единый API для извлечения информации из мультимодального контента: документов, изображений, видео и аудио. В отличие от классического OCR, BDA понимает контекст документа, проверяет извлечённые данные и выдаёт оценку уверенности (confidence score). Сервис автоматически разделяет документ на логические части, классифицирует каждый раздел по типу документа и сопоставляет их с соответствующими процессами обработки (blueprints). Blueprints — это предварительно настроенные артефакты, определяющие логику извлечения. BDA поддерживает документы объёмом до 3000 страниц и размером до 500 МБ на запрос, что позволяет обрабатывать разнообразные форматы в промышленных масштабах.
| Аспект | Традиционный OCR | Amazon Bedrock Data Automation |
|---|---|---|
| Извлечение | Только текст | Текст, таблицы, изображения, контекст |
| Понимание контекста | Нет | Да |
| Валидация данных | Нет | Да с оценкой уверенности |
| Классификация документов | Нет | Автоматическая по типам |
| Поддержка форматов | Ограниченный набор | Множество форматов, до 3000 страниц |
Архитектура решения, описанная в блоге AWS, включает четыре уровня. Уровень ввода обрабатывает загрузку документов в Amazon S3, запускает оркестрацию через AWS Step Functions и сохраняет метаданные в DynamoDB. Уровень извлечения и хранения использует BDA для извлечения текста, таблиц, изображений и визуальных элементов. Уровень интеллекта подключает базу знаний Amazon Bedrock Knowledge Base для семантического поиска и анализа с помощью мультимодальных фундаментальных моделей (FM) и больших языковых моделей (LLM). Уровень координации агентов использует агент Strands, работающий на Amazon Bedrock AgentCore Runtime, для распределения специализированных задач между несколькими агентами.
Поддерживает документы до 3000 страниц и 500 МБ на запрос.
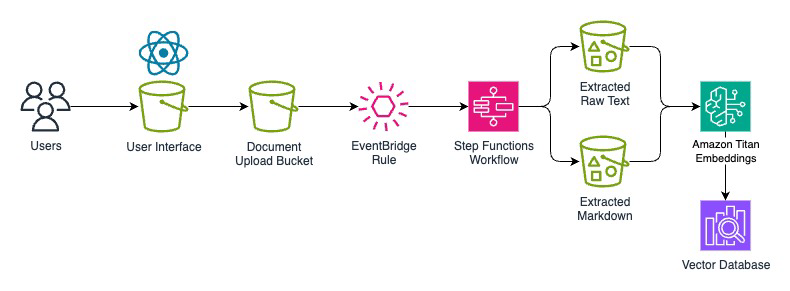
Ключевая особенность BDA — автоматическая маршрутизация на основе логических границ документа. Каждый документ разбивается на части до 20 страниц, каждая часть классифицируется по типу (например, счёт-фактура или страховой полис) и направляется к соответствующему blueprint. Это исключает необходимость ручной сортировки документов и оркестровки множества моделей ИИ. Полученные данные могут быть дополнительно обработаны агентами для построения отчётов, анализа трендов или интеграции с бизнес-приложениями.
Внедрение такого конвейера позволяет сократить затраты на ручную обработку, ускорить получение инсайтов из документов и масштабировать процессы без значительных усилий по разработке. Решение особенно актуально для отраслей с большим объёмом входящей документации: финансы, страхование, здравоохранение, юридические услуги.

