
Скачивание образа контейнера из Amazon ECR — один из главных источников задержки при масштабировании генеративных ИИ-сервисов. Для популярных контейнеров вроде SageMaker LMI или NVIDIA Triton размер образа достигает 15–18 ГБ в сжатом виде, и каждый новый инстанс тратил сотни секунд только на его загрузку. AWS решила эту проблему, предварительно размещая образы на инстансах до момента, когда они понадобятся.
Конкретные цифры выглядят так: модель Qwen3-8B (16 ГБ весов) на инстансе ml.g6.2xlarge с контейнером LMI весом 17,7 ГБ раньше требовала 333 секунды на скачивание образа и 168 секунд на загрузку весов из S3. Оба процесса шли параллельно, но конкурировали за пропускную способность сети, поэтому суммарное время старта составляло 525 секунд. После включения кеширования образ уже находится на диске, скачивание весов больше не делит канал с образом и укладывается в 77 секунд. Итог — 258 секунд, снижение на 51%.
| Клиент | Инстанс | Размер образа | Размер модели | P50 до (сек) | P50 после (сек) | Улучшение |
|---|---|---|---|---|---|---|
| Клиент 1 | ml.g4dn.xlarge | 15,7 ГБ | 0 ГБ | 381 | 134 | −65% |
| Клиент 2 | ml.g5.2xlarge | 17,5 ГБ | 5,8 ГБ | 346 | 164 | −52% |
| Клиент 3 | ml.g5.xlarge | 10,6 ГБ | 6,5 ГБ | 346 | 216 | −38% |
Данные от ранних пользователей подтверждают эффект на разных конфигурациях. Клиент на ml.g4dn.xlarge с образом 15,7 ГБ сократил P50-латентность с 381 до 134 секунд (−65%). Клиент на ml.g5.2xlarge с образом 17,5 ГБ и моделью 5,8 ГБ — с 346 до 164 секунд (−52%). Клиент на ml.g5.xlarge с образом 10,6 ГБ — с 346 до 216 секунд (−38%). Разброс объясняется разным соотношением размеров образа и модели: чем крупнее образ относительно весов, тем заметнее выигрыш.
Для Qwen3-8B на ml.g6.2xlarge время старта сократилось с 525 до 258 секунд — на 51%.
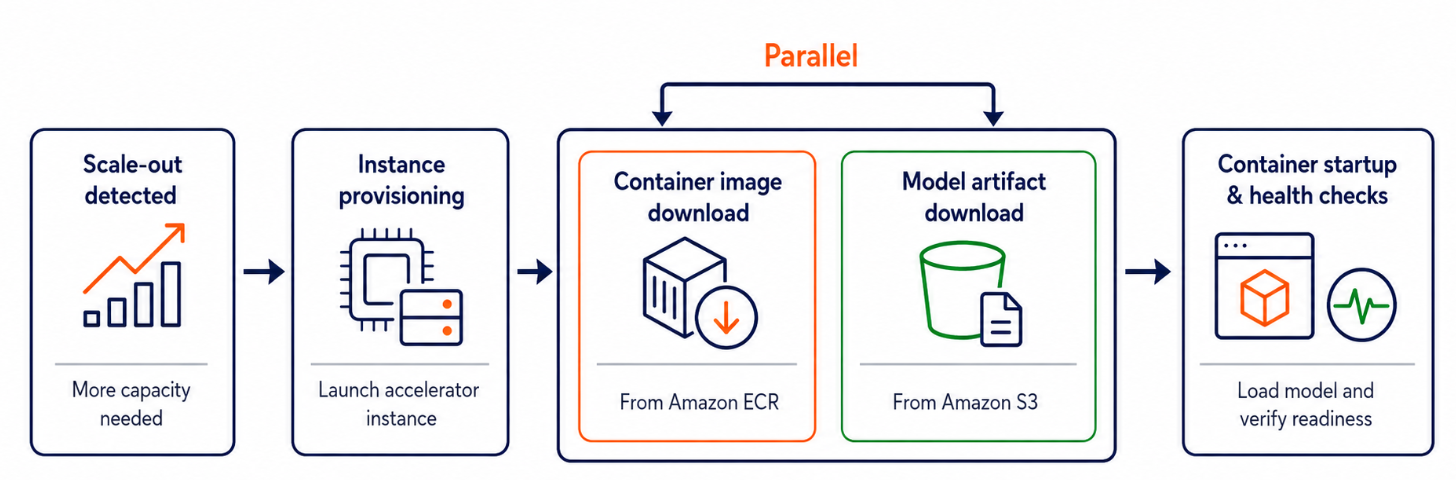
Новая функция — третья в серии оптимизаций автомасштабирования SageMaker ИИ. Первая — метрики с разрешением менее минуты для Amazon CloudWatch, которые позволяют обнаруживать потребность в масштабировании в 6 раз быстрее стандартных однаминутных метрик. Вторая — кеширование данных на уровне inference component: образы и веса хранятся на уже запущенных инстансах, что ускоряет добавление копий модели без запуска новых машин. Новое контейнерное кеширование закрывает оставшийся сценарий — когда свободных инстансов нет и нужно поднимать новые.
С точки зрения безопасности каждый кеш привязан к конкретному эндпоинту одного аккаунта AWS и не разделяется между клиентами. При удалении эндпоинта кеш очищается автоматически. Если по какой-то причине кешированный образ недоступен, SageMaker ИИ без ошибок откатывается к скачиванию из ECR — масштабирование не блокируется. Функция работает с любыми образами из Amazon ECR, включая кастомные, и не требует изменений в контейнере. Поддерживаются все инстансы с ускорителями во всех коммерческих регионах AWS, где доступен SageMaker ИИ inference.

