
При мониторинге LLM-эндоинтов, работающих под нагрузкой, сложно быстро определить причину скачка P99-задержки: виной может быть давление на GPU, насыщение KV cache, неравномерное распределение трафика по зонам доступности или не сработавшая авто-скалировка. Amazon SageMaker ИИ ответил на эти вызовы, добавив возможность включать детальную observability для инференс-эндоинтов — теперь доступно более 100 специализированных метрик.
Новые метрики охватывают здоровье GPU (использование памяти, утилизация ядер, температура), токенную задержку (time-to-first-token — TTFT, inter-token latency — ITL), давление KV cache (занятость кэша, количество hit и miss), распределение трафика по зонам доступности (AZ), холодный старт и ошибки недостаточной ёмкости. Для single-model эндоинтов (SME) и inference component эндоинтов (IC) метрики различаются: IC дают дополнительную информацию о размещении компонентов и копиях.
| Характеристика | Single-model endpoint (SME) | Inference component endpoint (IC) |
|---|---|---|
| Размещение моделей | Одна модель на выделенный экземпляр | Несколько моделей на общий пул экземпляров |
| Использование GPU | Фиксированное на модель, возможна фрагментация | Разделяемое, оптимизация утилизации |
| Масштабирование | Масштабируется весь эндоинт целиком | Независимое масштабирование каждой модели |
| Высокая доступность | Требует отдельных эндоинтов в разных AZ | Автоматическое распределение копий по AZ |
| Рекомендация для GenAI | Подходит для экспериментов и низких нагрузок | Рекомендован для production-нагрузок |
В CloudWatch появился встроенный дашборд SageMaker Insights, доступный в консоли CloudWatch под разделом Infrastructure Monitoring. Он использует PromQL для запросов к нативным OpenTelemetry-метрикам и отображает состояние на трёх вкладках. Performance показывает здоровье флота, токенную задержку, пропускную способность, ошибки и давление движка. Capacity — утилизацию GPU, CPU и памяти. Reliability — распределение по зонам доступности, события масштабирования, анатомию холодного старта и ошибки с недостатком ёмкости.
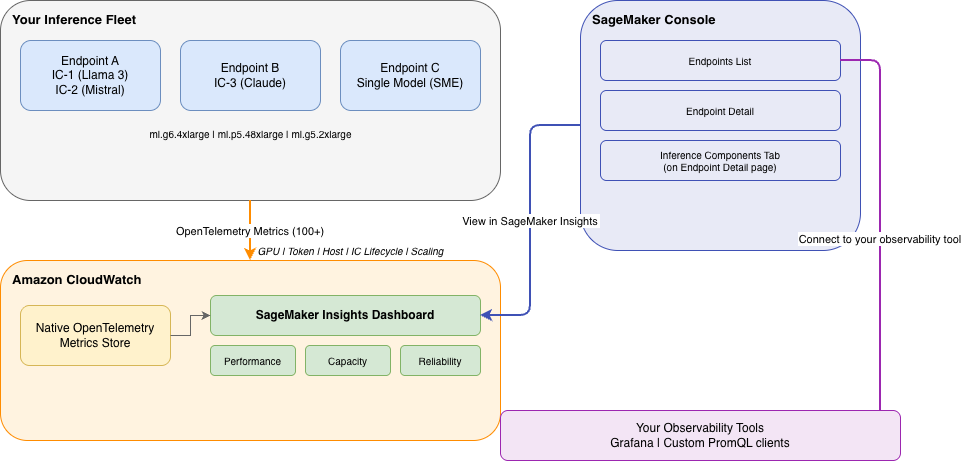
Для получения токенных метрик (TTFT, ITL) требуются фреймворки vLLM или SGLang. GPU-инстансы получают метрики на каждый ускоритель. Включение детальной observability для новых эндоинтов происходит автоматически — параметр EnableDetailedObservability по умолчанию равен true. Для существующих эндоинтов его можно активировать через обновление конфигурации. Инженерам MLOps и SRE не нужно отдельно настраивать Prometheus или Grafana — дашборд работает сразу. Однако при желании метрики можно экспортировать во внешние системы через PromQL-совместимый эндпоинт CloudWatch.
Inference component эндоинты (IC) — рекомендованная архитектура для production-нагрузок на генеративном ИИ, так как они позволяют размещать несколько моделей на общих GPU-инстансах, независимо масштабировать каждую модель и обеспечивать высокую доступность за счёт распределения копий по зонам доступности. Single-model эндоинты проще для понимания, но требуют выделенного флота под каждую модель. Новые метрики и дашборд работают с обоими типами, но для IC-эндоинтов автоматически отображаются дополнительные панели.
Это обновление существенно упрощает эксплуатацию LLM-инференса в AWS: команды могут быстрее выявлять узкие места, оптимизировать затраты на GPU-ресурсы и поддерживать SLA по задержкам. Решение появилось в ответ на растущую потребность в observability при переходе от обучения моделей к их промышленному использованию.


