
Спекулятивное декодирование — один из главных способов ускорить вывод больших языковых моделей без изменения их весов. Идея проста: лёгкая черновая модель предлагает несколько следующих токенов, а основная модель проверяет их все за один проход. Если черновик угадал — токены принимаются, и модель экономит время. Проблема в том, что сам черновик до сих пор работал последовательно: чтобы предложить четыре токена, он делал четыре прохода, каждый из которых зависел от результата предыдущего.
AWS решила эту проблему с помощью P-EAGLE (Parallel-EAGLE). Метод заменяет последовательные черновые проходы одним: вместо того чтобы ждать предыдущего токена, модель заполняет будущие позиции обучаемыми плейсхолдерами и предсказывает все токены одновременно. Если EAGLE нужно четыре прохода, чтобы предложить «, known for its» после «Paris», P-EAGLE делает это за один. Количество черновых токенов перестаёт влиять на задержку — она остаётся фиксированной вне зависимости от глубины спекуляции.
| Concurrency | P-EAGLE K=3 | P-EAGLE K=7 | P-EAGLE K=11 | EAGLE-3 K=3 | EAGLE-3 K=7 | EAGLE-3 K=11 | Baseline | P-EAGLE / EAGLE-3 | P-EAGLE / Baseline |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 665 | 1 032 | 1 167 | 651 | 905 | 955 | 294 | 1.22x | 3.97x |
| 4 | 2 205 | 3 313 | 3 710 | 2 198 | 3 044 | 3 215 | 889 | 1.15x | 4.17x |
| 8 | 3 958 | 5 786 | 6 252 | 3 979 | 5 493 | 5 589 | 1 587 | 1.12x | 3.94x |
AWS опубликовала метод в open-source и интегрировала его в Amazon SageMaker JumpStart. Бенчмарки проводились на модели Qwen3-Coder-30B-A3B-Instruct — это MoE-архитектура с 30 миллиардами параметров и активным подмножеством в 3 миллиарда — на GPU NVIDIA B200 с квантизацией FP8. На бенчмарке HumanEval при одном параллельном запросе P-EAGLE с K=11 выдаёт 1167 токенов в секунду против 955 у EAGLE-3 и 294 у базового инференса. На SPEED-Bench Code при concurrency=1 соотношение P-EAGLE к EAGLE-3 достигает 1,41x.
На бенчмарке HumanEval с Qwen3-Coder-30B-A3B-Instruct и NVIDIA B200 P-EAGLE K=11 даёт 1167 токенов/с против 955 у EAGLE-3 при concurrency=1.
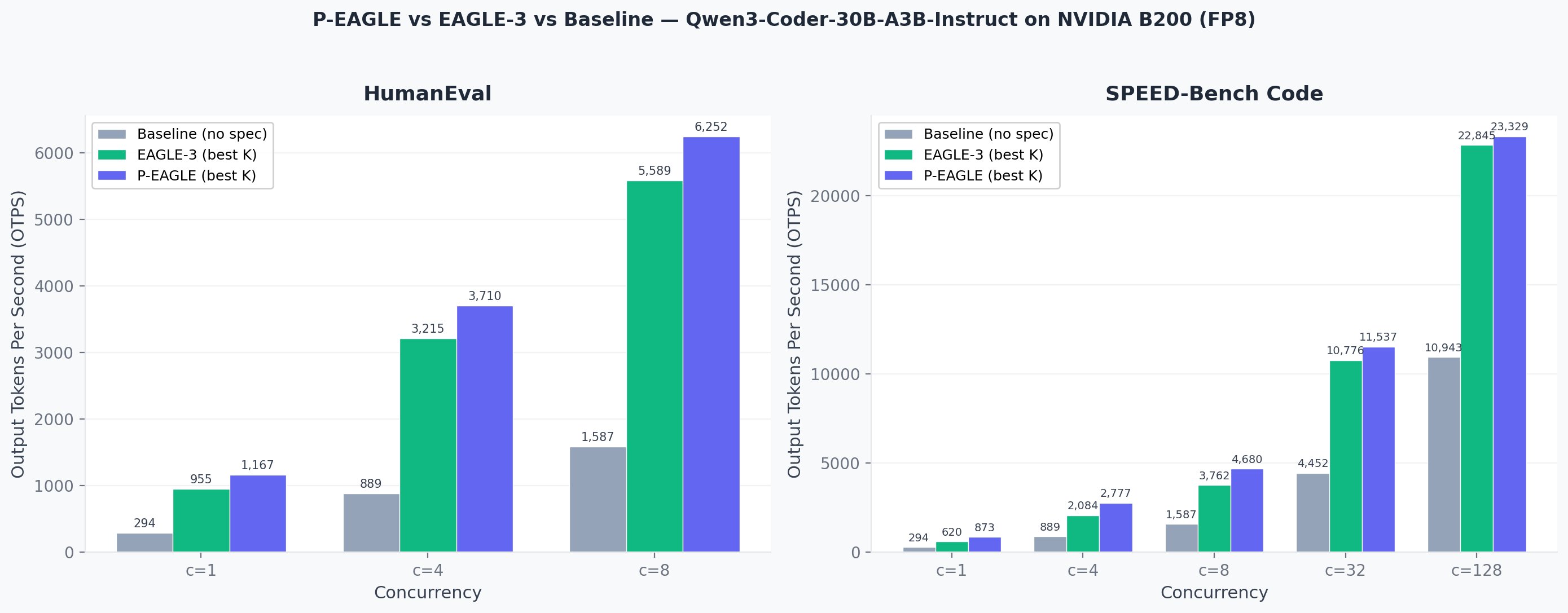
При росте нагрузки преимущество сглаживается: при 128 параллельных запросах на SPEED-Bench Code P-EAGLE опережает EAGLE-3 лишь на 2%, а базовый инференс — в 2,13x. Это ожидаемо: при высокой нагрузке GPU загружен полностью и выигрыш от параллельного черновика уменьшается. Наибольший эффект P-EAGLE даёт при низком и среднем concurrency — именно в этом режиме работает большинство интерактивных приложений.
P-EAGLE реализован как расширение архитектуры EAGLE-3. EAGLE-3 — последняя версия метода Extrapolation Algorithm for Greater Language-model Efficiency — предсказывает токены напрямую (а не скрытые представления, как ранние версии) и объединяет активации из нескольких слоёв целевой модели для повышения точности черновика. P-EAGLE сохраняет эту архитектуру, добавляя параллельный режим через единственный флаг parallel_drafting: true в конфигурации vLLM.
В SageMaker JumpStart на старте доступны четыре модели с предобученными P-EAGLE-головами: GPT-OSS-120B, GPT-OSS-20B, Qwen3-Coder-30B-A3B-Instruct и Gemma-4-31B-IT. Развёртывание не требует ручного обучения черновой модели, настройки CUDA-ядер или конфигурации распределённого сервинга — достаточно выбрать модель в каталоге и нажать Deploy. Параметр num_speculative_tokens задаёт, сколько токенов предсказывается за один параллельный проход; оптимальное значение зависит от задачи и уровня нагрузки.

