
Задача извлечения структурированных данных из отсканированных PDF — одна из самых распространённых в корпоративном секторе. Банки, страховщики, нефтяные компании и госструктуры накапливают десятки и сотни миллионов документов, которые хранятся как изображения без машиночитаемого текста. Ручная обработка нерентабельна, классические OCR-решения плохо справляются с вариативными форматами. AWS предложила архитектуру на базе Amazon Bedrock, которая решает эту задачу через два параллельных конвейера с общей логикой управления промптами.
Оба конвейера принимают сообщения из очередей Amazon SQS. Каждое сообщение содержит идентификатор документа, ID языковой модели и ссылку на промпт с указанием версии. Это позволяет обрабатывать разнородные документы в одном потоке: для одного файла используется промпт, заточенный под таблицы, для другого — под нумерованные списки или схемы земельных участков. Промпты хранятся в Amazon Bedrock Prompt Management, где каждый имеет уникальный ID и версионируется — сервис поддерживает до 50 промптов на регион и до 10 версий каждого.
| Параметр | On-demand конвейер | Batch конвейер |
|---|---|---|
| Тип SQS-очереди | FIFO | Стандартная |
| Гарантия однократной доставки | Да | Нет (дедупликация в коде) |
| Запуск | По входящему сообщению | По расписанию (EventBridge) |
| Минимум документов | 1 | 100 |
| Режим обработки | Синхронный, секунды | Асинхронный |
| Оптимизация | Скорость | Стоимость |
On-demand-конвейер построен на SQS FIFO-очереди, которая гарантирует однократную доставку сообщений и строгий порядок обработки. Входящее сообщение запускает Lambda-функцию: та скачивает PDF из S3, конвертирует страницы в PNG-изображения, получает нужный промпт и отправляет запрос в Bedrock через Converse API. Модель возвращает извлечённые данные в формате JSON, которые сохраняются в DynamoDB. Ограничение текущей версии Claude 4 Sonnet — не более 20 изображений за один вызов — обходится автоматическим разбиением документа на чанки по 20 страниц; для каждого чанка в DynamoDB фиксируются doc_id, chunk_count и chunk_id.
Пакетный режим запускается по расписанию через EventBridge и требует минимум 100 документов на одно задание Bedrock.
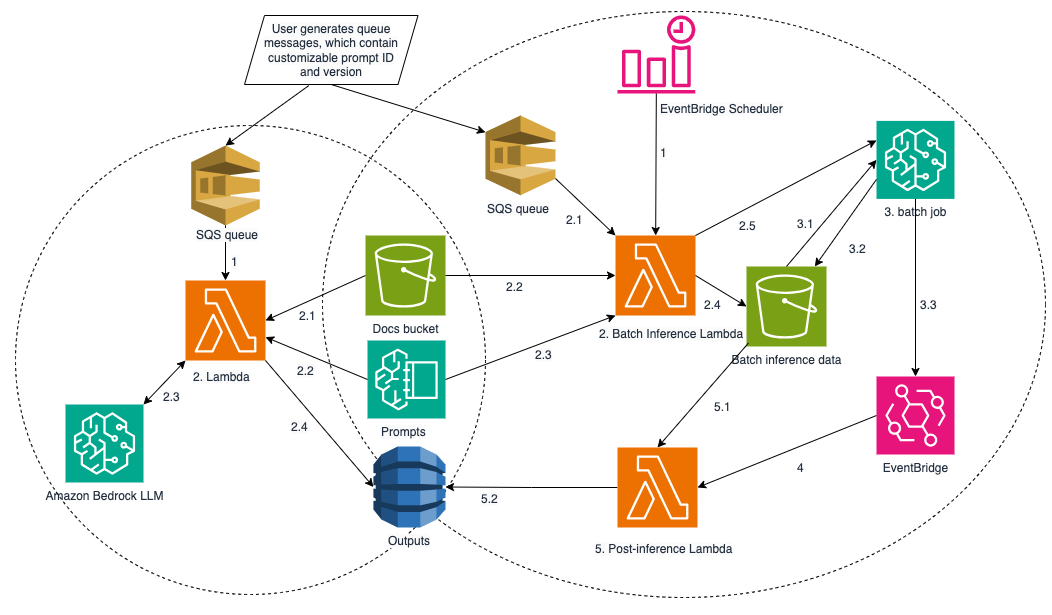
Пакетный конвейер ориентирован на экономию: он запускается по расписанию через Amazon EventBridge Scheduler и обрабатывает документы асинхронно. Минимальный порог для запуска одного задания Bedrock Batch Inference — 100 документов. Lambda-функция накапливает сообщения из стандартной SQS-очереди (без гарантии FIFO), формирует JSONL-файл и отправляет пакетное задание. Поскольку стандартная очередь не гарантирует однократную доставку, функция дополнительно фильтрует дубликаты. После завершения задания отдельная Lambda, запускаемая через правило EventBridge, выполняет постобработку результатов.
Архитектура отражает типичный компромисс между скоростью и стоимостью в облачных ML-пайплайнах. On-demand-режим подходит для срочных запросов — например, когда результат нужен пользовательской сессии. Пакетный режим снижает затраты за счёт асинхронности: Amazon Bedrock Batch Inference тарифицируется дешевле on-demand-вызовов. Возможность динамически менять модель и промпт на уровне каждого документа даёт гибкость, которой не хватает большинству монолитных OCR-решений: при появлении новой версии модели или улучшенного промпта не нужно перестраивать весь конвейер.