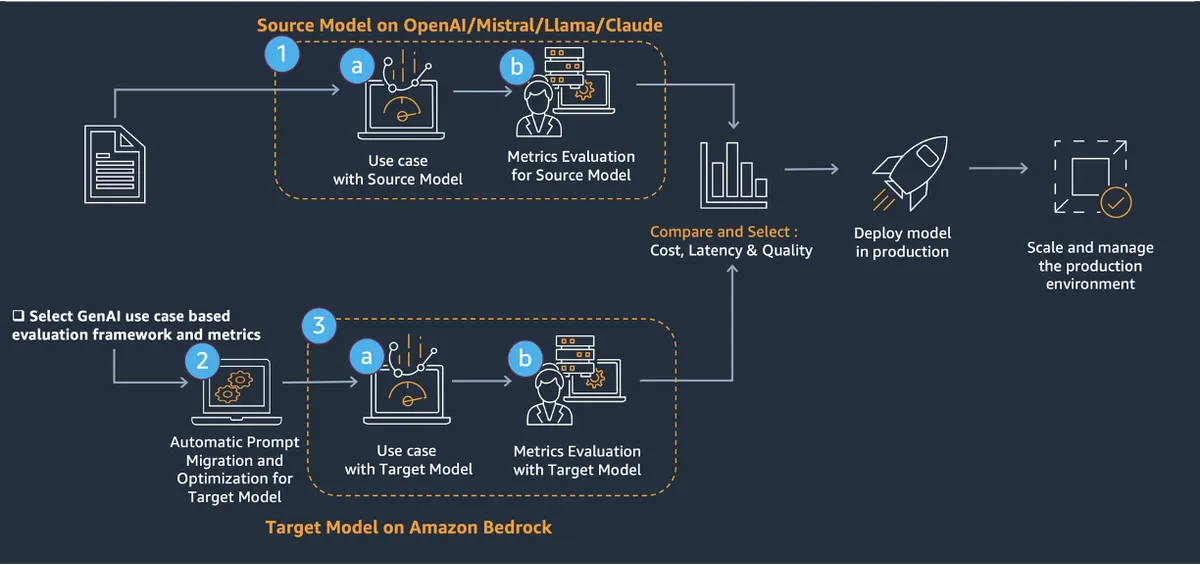
Переход с одной языковой модели на другую в производственной среде — задача, которую большинство команд решают вручную и без чёткой методологии. AWS предложила системный ответ: фреймворк Model Agility Solution, описанный в блоге AWS Machine Learning Blog, задаёт единый процесс миграции от подготовки данных до финальной валидации результата.
В основе подхода — трёхшаговая схема. Сначала команда оценивает исходную модель по набору метрик, фиксируя базовые показатели качества, задержки и стоимости. Затем промпты переносятся на целевую модель и оптимизируются — для этого фреймворк предлагает два инструмента: Amazon Bedrock Prompt Optimization и Anthropic Metaprompt. Наконец, целевая модель проходит те же тесты, что и исходная, что позволяет сравнить их напрямую. Весь цикл занимает от двух дней до двух недель в зависимости от сложности сценария.
| Параметр выбора модели | Что оценивается |
|---|---|
| Модальности | Текст, код, мультимодальность |
| Контекстное окно | Максимальное число токенов на входе |
| Стоимость | Цена за инференс или за токен |
| Производительность | Задержка и пропускная способность |
| Качество вывода | Точность и соответствие предметной области |
| Размещение | Облако, on-premises, гибрид |
| Безопасность | Требования к конфиденциальности данных |
Ключевой элемент процесса — качество оценочного датасета. AWS рекомендует включать в него не только вопросы и эталонные ответы, но и конфигурации вызова исходной модели (temperature, top_p, top_k), токены ввода и вывода для расчёта стоимости, а также уже накопленные оценки — как автоматические (LLM-as-a-judge), так и человеческие (оценки экспертов, отметки «нравится/не нравится»). Без качественных эталонных ответов большинство метрик точности попросту не работают.
Для автоматической оптимизации промптов используются Amazon Bedrock Prompt Optimization и инструмент Anthropic Metaprompt.
Для сценариев, где эталонные ответы недоступны, фреймворк предусматривает метрики, не требующие ground truth: релевантность ответа, достоверность (faithfulness), токсичность и предвзятость. Это делает подход применимым, например, к задачам генерации контента или суммаризации, где однозначно «правильного» ответа не существует.
При выборе целевой модели фреймворк предлагает оценивать несколько характеристик: поддерживаемые модальности (текст, код, мультимодальность), размер контекстного окна, стоимость инференса, задержку и пропускную способность, а также совместимость с конкретной предметной областью. После первичной фильтрации рекомендуется провести бенчмаркинг на задачах, специфичных для целевого сценария. Amazon Bedrock здесь выступает единой точкой доступа: через один API можно запускать несколько моделей параллельно и сравнивать их результаты без изменения архитектуры интеграции.
Фреймворк решает проблему, с которой сталкиваются команды при смене поставщика модели или переходе на новую версию внутри одного семейства: промпты, написанные под одну модель, нередко дают заметно худшие результаты на другой из-за различий в форматировании инструкций и поведении модели. Автоматизированная оптимизация промптов снижает ручную работу, хотя фреймворк оговаривает, что инструменты дополняют, а не заменяют экспертную настройку.


