
AWS опубликовала подробную референсную архитектуру, в которой агентный ИИ-ассистент превращает запросы на естественном языке в аналитику по корпоративным данным. Основу стенда составляет эталонный датасет TPC-H — стандартный benchmark для реляционных баз данных, содержащий таблицы заказов, клиентов и позиций накладных. AWS разместила его в публичном S3-бакете (s3://redshift-downloads/TPC-H/2.18/100GB) объёмом 100 ГБ.
Архитектура состоит из нескольких слоёв. Нижний — хранилище на Amazon S3 в трёх форматах одновременно. Первый — обычные CSV-файлы, доступные через внешние таблицы Athena без копирования данных. Второй — Apache Iceberg, открытый табличный формат с поддержкой ACID-транзакций, «путешествий во времени» (time travel) и эволюции схемы, что делает его пригодным для продакшн-нагрузок. Третий — Amazon S3 Tables, сервис с нативной поддержкой Iceberg прямо на уровне объектного хранилища, который AWS позиционирует как упрощение lakehouse-архитектуры в масштабе.
| Формат хранения | Тип таблицы | Ключевые возможности |
|---|---|---|
| CSV на Amazon S3 | Внешняя таблица Athena | Запросы без копирования данных, низкая стоимость старта |
| Apache Iceberg (Parquet) | Управляемая OTF-таблица | ACID-транзакции, time travel, эволюция схемы |
| Amazon S3 Tables | Нативная Iceberg-таблица | Встроенная поддержка Iceberg на уровне S3, масштабирование |
Поверх хранилища работает AWS Glue Catalog — единый реестр метаданных для всех трёх форматов. Amazon Athena выполняет serverless SQL-запросы к любому из них через этот каталог, не требуя отдельной инфраструктуры. Результаты запросов поступают в Amazon QuickSight, где загружаются в SPICE — собственный in-memory движок QuickSight — и становятся основой для интерактивных дашбордов.
Данные хранятся в трёх форматах: CSV (внешние таблицы), Apache Iceberg с поддержкой ACID-транзакций и S3 Tables с нативной поддержкой Iceberg.
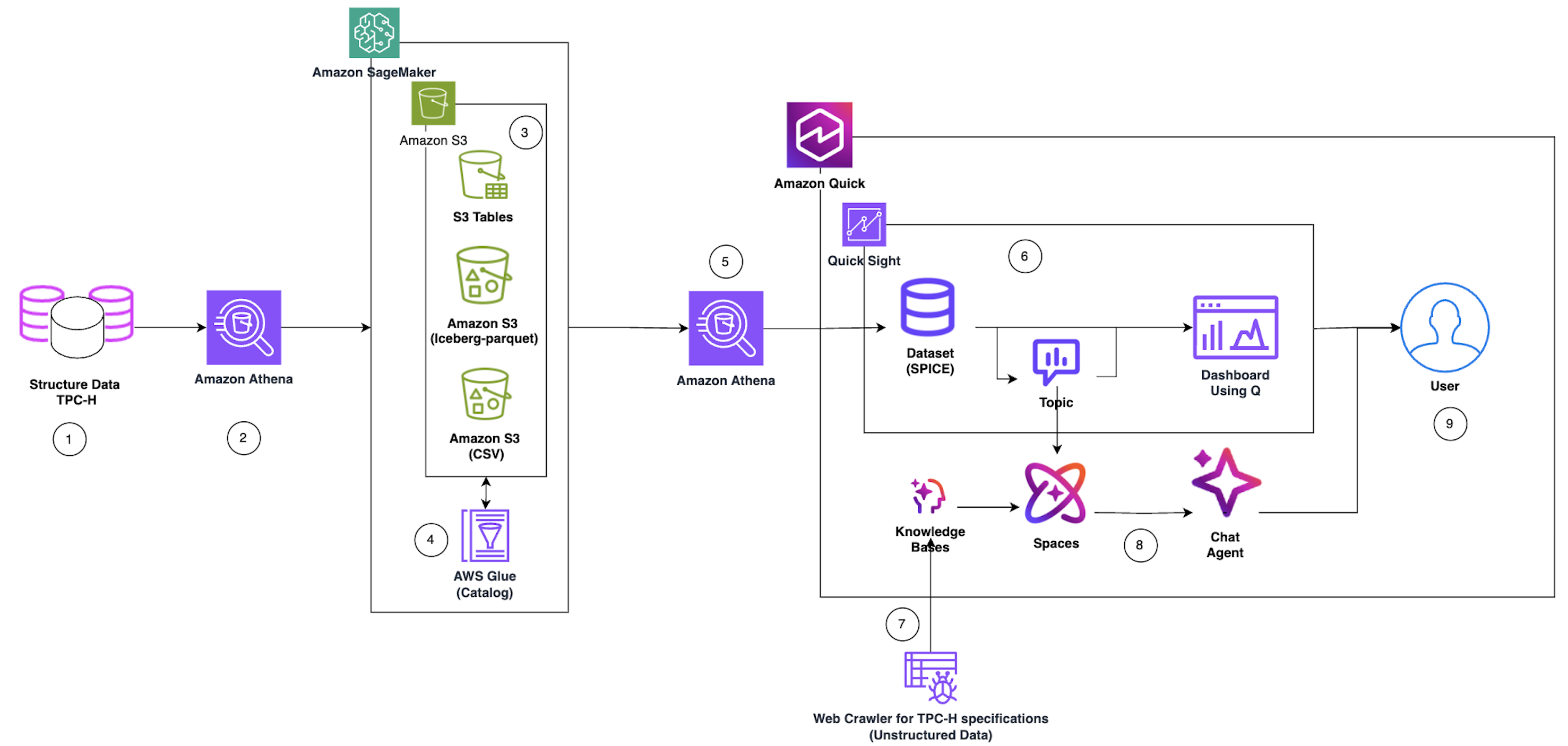
Ключевой элемент архитектуры — агентный слой. Параллельно со структурированными данными веб-краулер индексирует неструктурированные документы: спецификации TPC-H, техническую документацию. Эти материалы попадают в базы знаний Amazon QuickSight, которые снабжают чат-агента контекстом предметной области. В итоге пользователь может задать вопрос вроде «Какие клиенты принесли наибольшую выручку в прошлом квартале?» и получить ответ без единой строки SQL.
Подобный подход решает давнюю проблему корпоративной аналитики: узкое место в виде аналитиков и дата-инженеров, которые переводят бизнес-вопросы в запросы к базам данных. Аналогичные решения развивают Databricks (с ассистентом на базе собственных LLM), Snowflake (Cortex Analyst) и Microsoft (Copilot в Power BI). AWS делает ставку на глубокую интеграцию собственных сервисов: SageMaker как платформа для оркестрации, Athena как serverless SQL-движок и QuickSight как фронтенд для бизнес-пользователей.
С точки зрения разработчика архитектура предполагает последовательную настройку: создание базы данных в Glue через Athena-запрос CREATE DATABASE, определение внешних таблиц поверх S3-данных без их перемещения, затем создание Iceberg-таблиц для транзакционных сценариев. AWS подчёркивает, что внешние таблицы Athena не копируют данные — они запрашивают их напрямую из S3, что снижает затраты на начальном этапе экспериментов. Для хранения результатов запросов Athena требует отдельный S3-бакет в том же регионе, что и источники данных, — это позволяет избежать межрегиональных расходов на передачу данных.


