
На Amazon SageMaker AI стали доступны инстансы G7e, оснащённые GPU NVIDIA RTX PRO 6000 Blackwell Server Edition. Конфигурации включают 1, 2, 4 и 8 карт; каждая несёт 96 ГБ GDDR7-памяти с пропускной способностью 1597 ГБ/с. Максимальная конфигурация — g7e.48xlarge с 8 GPU — аккумулирует 768 ГБ видеопамяти и поддерживает сетевой интерфейс EFA на скорости 1600 Гбит/с.
Для понимания масштаба изменений полезно сравнение поколений. У G5 (NVIDIA A10G) на каждую карту приходилось 24 ГБ GDDR6-памяти и 600 ГБ/с пропускной способности, у G6e (NVIDIA L40S) — 48 ГБ и 864 ГБ/с. G7e удваивает эти показатели относительно G6e и учетверяет относительно G5. Сетевая пропускная способность выросла с 400 Гбит/с у G6e до 1600 Гбит/с у G7e — рост в четыре раза. Это принципиально меняет возможности многоузловых сценариев: задержки при обмене данными между GPU снижаются настолько, что распределённый инференс и дообучение крупных моделей становятся практически применимыми на G-серии.
| Spec | G5 (g5.48xlarge) | G6e (g6e.48xlarge) | G7e (g7e.48xlarge) |
|---|---|---|---|
| GPU | 8x NVIDIA A10G | 8x NVIDIA L40S | 8x NVIDIA RTX PRO 6000 Blackwell |
| GPU Memory per GPU | 24 GB GDDR6 | 48 GB GDDR6 | 96 GB GDDR7 |
| Total GPU Memory | 192 GB | 384 GB | 768 GB |
| GPU Memory Bandwidth | 600 GB/s per GPU | 864 GB/s per GPU | 1,597 GB/s per GPU |
| vCPUs | 192 | 192 | 192 |
| System Memory | 768 GiB | 1,536 GiB | 2,048 GiB |
| Network Bandwidth | 100 Gbps | 400 Gbps | 1,600 Gbps (EFA) |
| Local NVMe Storage | 7.6 TB | 7.6 TB | 15.2 TB |
| Inference vs. G6e | Baseline | ~1x | Up to 2.3x |
Ключевое следствие роста памяти — изменение порогов для размещения моделей. На одном инстансе G7e.2xlarge в формате FP16 помещается модель с 35 млрд параметров, на четырёх GPU — до 150 млрд, на восьми — до 300 млрд. Ранее модели такого масштаба требовали многоузловых кластеров на G5 или G6e, что увеличивало операционную сложность и вносило задержки на межузловую коммуникацию. AWS указывает, что G7e поддерживает запуск open-source моделей GPT-OSS-120B, Nemotron-3-Super-120B-A12B в варианте NVFP4 и Qwen3.5-35B-A3B на единственном узле.
Производительность инференса до 2,3× выше по сравнению с G6e при сетевой пропускной способности до 1600 Гбит/с.
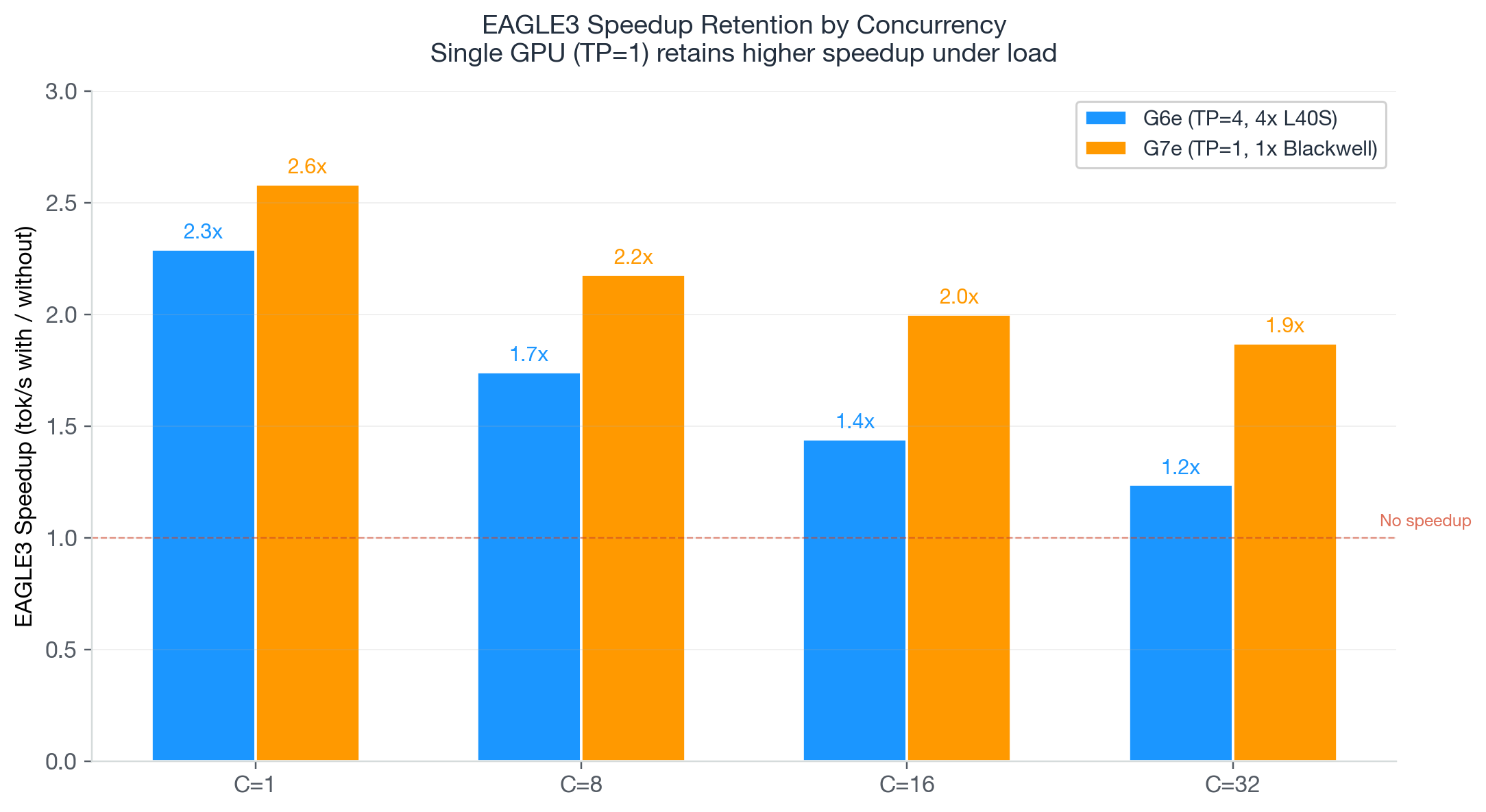
Benchmark на модели Qwen3-32B (BF16) демонстрирует экономическую логику выбора между поколениями. G6e.12xlarge с четырьмя L40S при нагрузке C=32 выдаёт 686 токенов в секунду суммарно при стоимости $2,06 за миллион токенов и часовой ставке $13,12. G7e.2xlarge с одним RTX PRO 6000 при той же нагрузке генерирует 592 токена в секунду при стоимости $0,79 за миллион токенов и ставке $4,20/ч. Снижение стоимости — 2,6× — достигается за счёт отсутствия накладных расходов на межкарточную синхронизацию: при tensor parallelism degree 1 нет операций all-reduce на каждом слое трансформера, нет фрагментации KV-кеша между GPU и нет узкого места NVLink. Латентность при росте нагрузки с C=1 до C=32 увеличивается на 22% (с 27,2 до 33,2 с) против 62% у G6e (с 16,1 до 26,0 с) — поведение под нагрузкой предсказуемее.
Для задач с жёсткими требованиями к латентности при низкой конкурентности G6e по-прежнему быстрее на отдельный запрос: четыре параллельных GPU обрабатывают запрос за 16,1 с против 27,2 с у одиночного G7e. Однако для производственных систем, где важна стоимость токена при высокой нагрузке, G7e выигрывает. AWS также описывает совместное применение G7e со спекулятивным декодированием EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency) — метод предсказывает несколько следующих токенов из внутренних представлений модели и верифицирует их за один прямой проход, что даёт дополнительный прирост производительности поверх аппаратных улучшений.
G7e поддерживает FP4-точность через Tensor Cores пятого поколения — это позволяет запускать квантизованные варианты крупных моделей с меньшими потерями качества, чем при INT8. Среди заявленных сценариев — чат-боты и диалоговые системы, RAG-пайплайны с быстрой инъекцией контекста из векторных хранилищ, генерация и суммаризация длинных документов (96 ГБ памяти вмещают большие KV-кеши для расширенного контекста), мультимодальные модели и задачи физического ИИ, включая цифровые двойники и 3D-симуляции.


