
Компания Loka разработала голосового агента на основе Amazon Nova 2 Sonic — native speech-to-speech модели, которая обрабатывает аудиопоток без промежуточного преобразования в текст. Решение предназначено для сценариев, где важна естественность диалога, например в автосалонах. Проблема традиционных голосовых ассистентов — трёхэтапный пайплайн (распознавание речи, обработка текста в LLM, синтез речи), который вносит задержку в 3–5 секунд. Кроме того, при переводе звука в текст теряются тон, хезитация и интонация. Нативный аудиоподход устраняет эти потери, передавая акустические особенности напрямую.
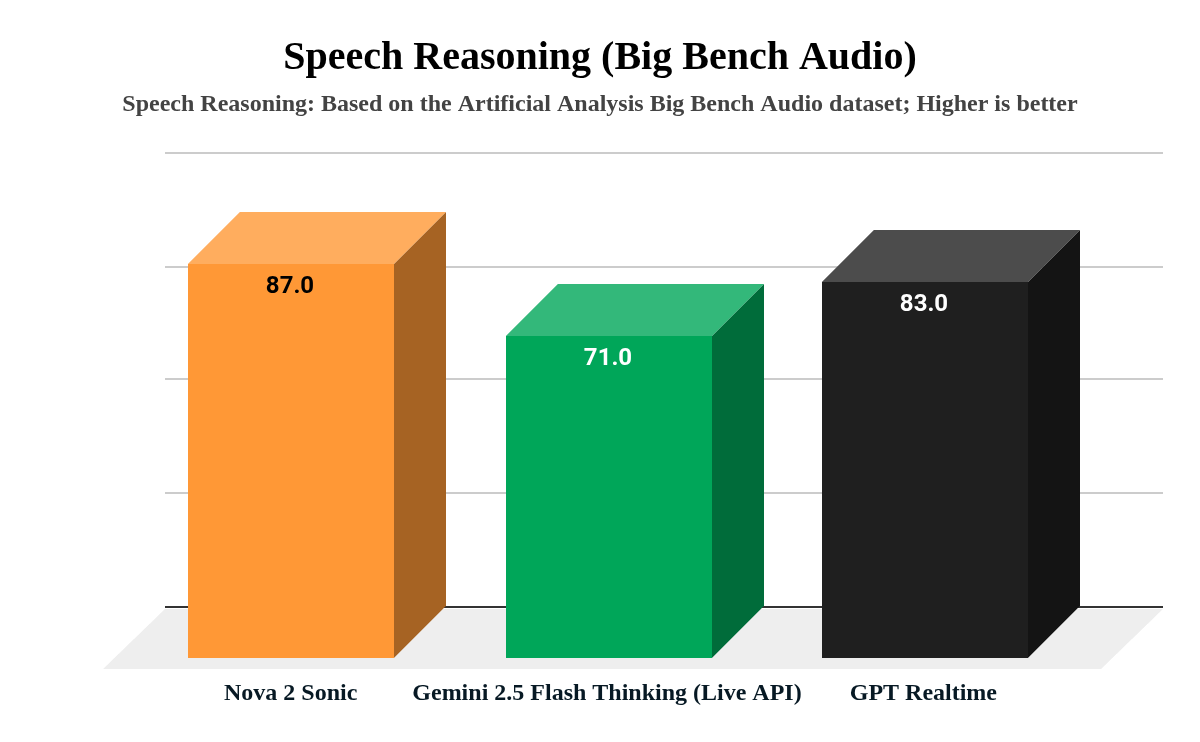
Для оценки качества Loka использовала бенчмарк Big Bench Audio, измеряющий способность рассуждать на основе речевых сигналов. Amazon Nova 2 Sonic набрала 87 баллов, опередив GPT Realtime (83) и Gemini 2.5 Flash Native Audio (71). Время первого аудио составило 1,39 секунды — это позволяет реализовать естественное перебивание (barge-in), когда пользователь может прервать ассистента без задержки. Стоимость обработки — $0,27 за час входного аудио, что ниже как традиционных пайплайнов, так и других real-time моделей.
| Модель | Speech reasoning (Big Bench Audio) |
|---|---|
| Amazon Nova 2 Sonic | 87.0 |
| GPT Realtime | 83.0 |
| Gemini 2.5 Flash Native Audio | 71.0 |
Дополнительно Loka провела автоматическую оценку по пяти критериям с помощью LLM-судьи. Сравнение Amazon Nova Sonic и Amazon Nova 2 Sonic показало улучшение релевантности ответов (с 2,5 до 2,9), понимания намерений (с 2,9 до 3,0), полноты (с 1,8 до 2,5), естественности диалога (с 2,5 до 2,8) и общего балла (с 2,4 до 2,7). Таким образом, агент на Nova 2 Sonic не только быстрее и дешевле, но и эффективнее выполняет задачи клиентов.
На бенчмарке Big Bench Audio модель набрала 87 баллов, опередив GPT Realtime (83) и Gemini 2.5 Flash (71).
Хотя Loka фокусируется на автомобильных дилерских центрах, описанная архитектура применима к любым голосовым интерфейсам, где важны низкая задержка, естественность и контроль затрат. Неопределённость остаётся в масштабировании на тысячи одновременных сессий и точной оценке качества в условиях реальной эксплуатации за пределами бенчмарков.


