
Дообучение с подкреплением (Reinforcement Fine-Tuning, RFT) стало стандартным способом выравнивания языковых моделей под конкретные задачи. Классический вариант — RLVR — использует верифицируемые награды: код проверяет, правильно ли модель решила задачу. Но когда критерии качества размыты — например, «ответ должен звучать профессионально и цитировать авторитетные источники» — написать такую проверку вручную почти невозможно. Именно здесь появляется RLAIF: вместо кода ответы оценивает отдельная языковая модель.
Модель-судья работает принципиально иначе, чем числовая метрика. Она анализирует ответ сразу по нескольким осям — корректность, тон, безопасность, соответствие вопросу — и возвращает структурированную оценку с обоснованием. Фраза вроде «Ответ A ссылается на рецензируемые исследования» даёт разработчику конкретную точку для итерации, которую статическая функция награды предоставить не может. AWS применяет этот подход к семейству Amazon Nova и описывает шесть шагов его реализации.
| Критерий | Рубрикальный судья | Предпочтительный судья |
|---|---|---|
| Метод оценки | Числовой балл за один ответ по заданным критериям | Сравнение двух ответов, выбор лучшего |
| Тип измерения | Абсолютное качество | Относительное качество через сравнение |
| Когда применять | Есть чёткие, измеримые критерии (точность, безопасность) | Есть сравнительные данные или образцы ответов |
| Требования к данным | Только тщательный промпт-инжиниринг | Нужен хотя бы один эталонный ответ для сравнения |
| Обобщаемость | Лучше для нестандартных данных, меньше смещения | Зависит от качества эталонных ответов |
| Рекомендация | Отправная точка при отсутствии данных для сравнения | Использовать при наличии сравнительных данных |
Первый шаг — выбор архитектуры судьи. Существует два режима: рубрикальный (rubric-based) и предпочтительный (preference-based). Рубрикальный присваивает числовой балл одному ответу по заранее определённым критериям; предпочтительный сравнивает два ответа и выбирает лучший. Рубрикальный подход рекомендован как отправная точка, если нет готовых данных для сравнения. AWS особо советует булеву (да/нет) систему оценки вместо шкалы от 1 до 10: она стабильнее и меньше зависит от случайных колебаний в поведении судьи.
Модель-судья объясняет свои оценки через обоснования, что ускоряет итерации и помогает выявлять скрытые ошибки.
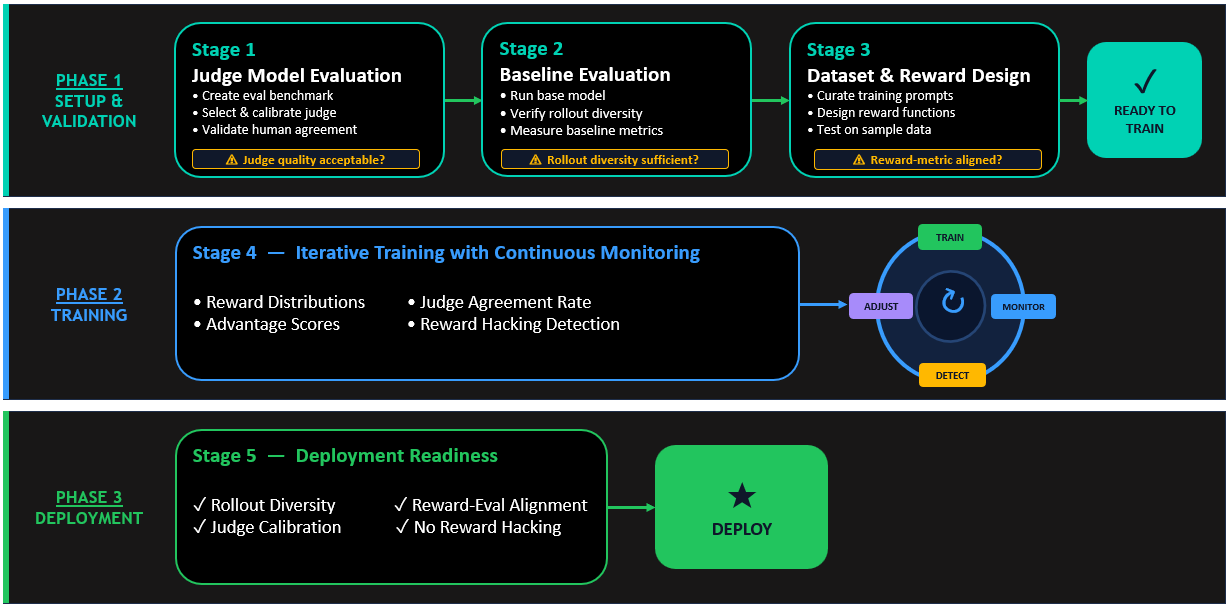
Второй шаг — формулировка критериев оценки. Для предпочтительного судьи достаточно чёткого промпта: «Предпочитай ответы, которые цитируют авторитетные источники, используют доступный язык и прямо отвечают на вопрос пользователя». Для рубрикального нужно прописать конкретные, наблюдаемые признаки прохождения каждого критерия.
Третий шаг — выбор модели-судьи. AWS предлагает двухуровневую схему. Для сложных задач с многомерной оценкой — тяжёлые модели: Amazon Nova Pro, Claude Opus, Claude Sonnet. Для типовых доменов вроде математики или кода — лёгкие: Amazon Nova 2 Lite, Claude Haiku. Разница не только в качестве, но и в стоимости: лёгкие модели существенно дешевле при сопоставимой надёжности на простых задачах.
Четвёртый шаг — проектирование промпта судьи. Он должен возвращать структурированный, машиночитаемый вывод (JSON), содержать явные правила для каждого измерения и обрабатывать граничные случаи — например, «если ответ пустой, присвоить 0».
Пятый шаг — согласование критериев судьи с продуктовыми метриками. Функция награды должна отражать те же показатели, по которым модель будет оцениваться в продакшне. AWS рекомендует сначала определить пороговые значения для точности и безопасности, затем сопоставить каждый критерий с измерением судьи и проверить корреляцию на репрезентативных примерах.
Шестой шаг — построение отказоустойчивой Lambda-функции. Производственные системы RFT выполняют тысячи оценок за один шаг обучения. AWS советует не полагаться исключительно на LLM-судью: перед дорогостоящим вызовом модели стоит запускать быстрые детерминированные проверки — валидацию JSON-структуры, штрафы за длину, проверку языка ответа, фильтры запрещённого контента. Для устойчивости к сбоям рекомендуется экспоненциальный backoff при ошибках API, параллельные вызовы через ThreadPoolExecutor, таймаут Lambda в 15 минут и provisioned concurrency около 100 экземпляров. При неустранимых ошибках функция должна возвращать нейтральную награду (0.5), а не ломать обучение.
Подход RLAIF не нов — он восходит к работам Anthropic по Constitutional AI и более ранним исследованиям по RLHF, где человеческих оценщиков заменяли моделью. AWS адаптирует эту идею под собственную инфраструктуру Bedrock и предлагает конкретный инженерный рецепт, пригодный для команд, которые хотят выравнивать модели без масштабной разметки данных.


