
Когда ИИ-агент в продакшне начинает ошибаться, команда обычно видит только итог: goal success rate упал с 85% до 70%. Дальше начинается ручная работа — инженер открывает трассировки, просматривает сотни спанов и пытается понять, где именно сломалась логика. AWS предлагает автоматизировать этот процесс с помощью Detectors — нового компонента Strands Evals SDK.
Detectors работают в два последовательных этапа. На первом функция detect_failures сканирует каждый спан сессии и сопоставляет его с таксономией из девяти родительских категорий сбоев: галлюцинации, некорректные действия, ошибки оркестрации, несоответствие инструкциям задачи, ошибки выполнения, ошибки обработки контекста, повторяющееся поведение, проблемы с выводом LLM и несоответствие конфигурации. Для каждого выявленного сбоя возвращается идентификатор спана, одна или несколько категорий, оценка уверенности и доказательство, извлечённое из трассировки.
| Категория сбоя | Пример из демо | Оценка уверенности |
|---|---|---|
| execution-error-category-tool-schema | Отсутствует обязательный параметр knowledgeBaseId | 0.9 |
| hallucination-category-hall-usage | Агент отвечает «из общих знаний», не используя инструменты | 0.75 |
| orchestration-related-errors-category-goal-deviation | Агент переключается на тему морской биологии вместо задачи | 0.9 |
На втором этапе функция analyze_root_cause берёт список обнаруженных сбоев и выстраивает причинно-следственные цепочки. Один сбой в начале цепочки нередко порождает несколько симптомов ниже по потоку. Инструмент присваивает каждому сбою статус PRIMARY, SECONDARY или TERTIARY, оценивает масштаб распространения и формирует рекомендацию: что именно менять — системный промпт, описание инструмента или что-то иное.
Каждый сбой получает метку категории, оценку уверенности (confidence score) и доказательство из трассировки — без ручного просмотра логов.
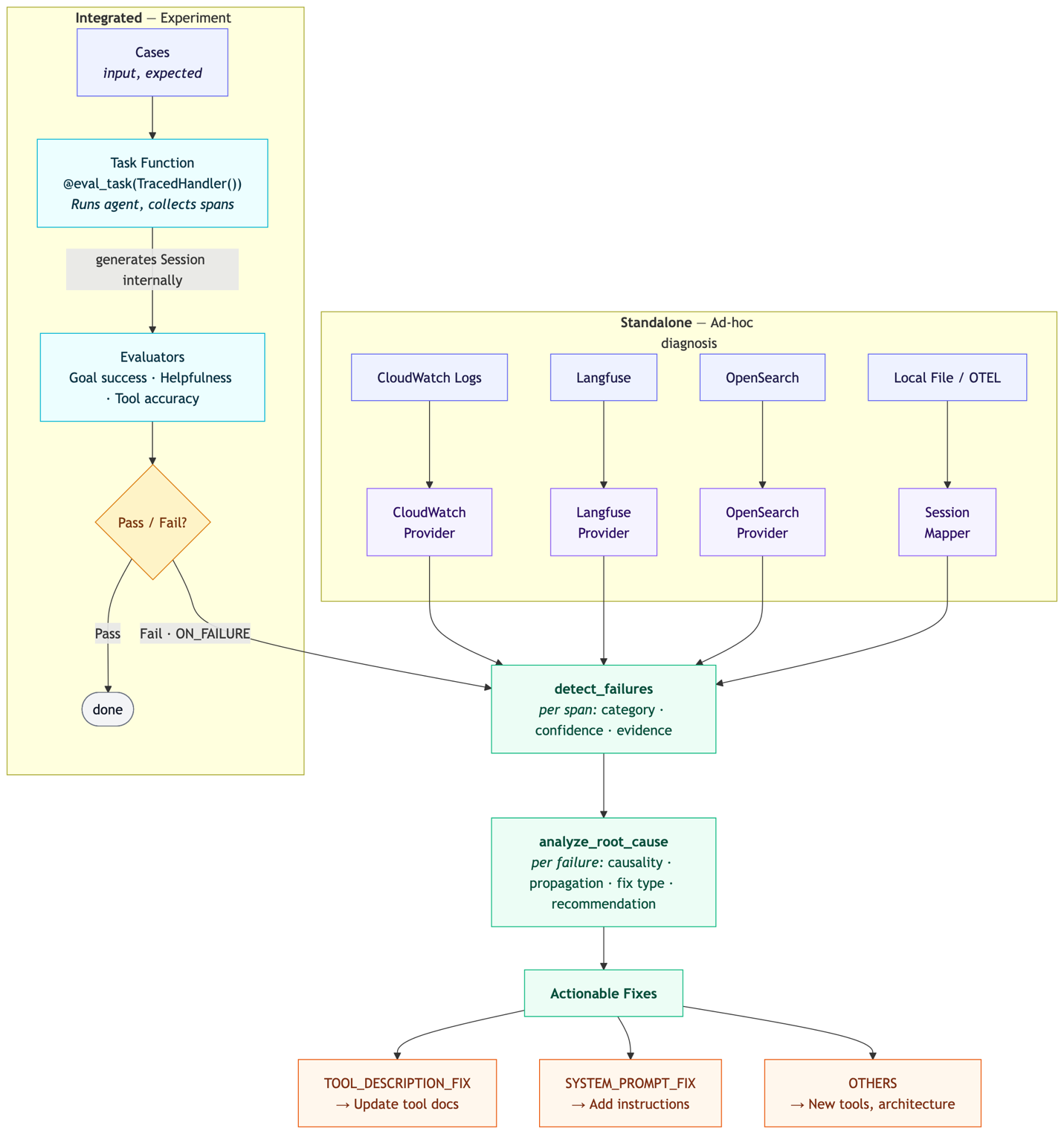
В демонстрационном примере из публикации агент-исследователь получил задание изучить энергопотребление ИИ-систем. Детектор за один проход выявил три уровня деградации: ошибку выполнения (инструмент упал из-за отсутствия обязательного параметра knowledgeBaseId с оценкой уверенности 0,9), семантическую проблему (агент заявил об отсутствии доступа к базе знаний, а затем выдал развёрнутый ответ «из общих знаний» — оценка 0,75) и полное отклонение от цели (агент переключился на рассказ о морской биологии — оценка 0,9). Каждый спан может одновременно нести несколько категорий сбоев с независимыми оценками.
Для работы с большими сессиями SDK применяет три стратегии в зависимости от объёма трассировки: прямой анализ, если сессия умещается в контекстное окно выбранной модели; обрезку пути сбоя с сохранением только предков и потомков проблемных спанов для средних сессий; чанкованный анализ с перекрывающимися окнами и последующим объединением результатов для очень больших сессий.
Detectors дополняют, а не заменяют существующие метрики Strands Evals — Cases, Experiments и Evaluators. Если Evaluators отвечают на вопрос «насколько хорошо агент справился?», то Detectors отвечают на вопрос «почему он ошибся и что исправить?». Интеграция в пайплайн оценки позволяет запускать диагностику автоматически на каждом тестовом прогоне, а не только при ручном расследовании инцидентов. Источником трассировок может служить как локальный JSON-файл с OpenTelemetry-данными, так и Amazon CloudWatch через CloudWatchProvider — для этого нужны права logs:StartQuery и logs:GetQueryResults.

