
Sun Finance — латвийский финтех, основанный в 2017 году и работающий как онлайн-маркетплейс кредитования в девяти странах. Компания выдаёт более 4 млн оценок кредитоспособности в месяц и принимает новую заявку каждые 0,63 секунды. В одном из ключевых регионов, где ежемесячно поступает 80 000 заявок на микрозаймы, около 60% из них не проходили автоматическую проверку и попадали к операторам. Три штатных сотрудника занимались только верификацией документов в этом регионе — и это блокировало масштабирование в сегменты с низкой маржой.
Проблема была не в мошенниках, а в OCR. Из всех случаев ручной проверки 80% возникали из-за расхождений между данными, которые клиент ввёл вручную, и тем, что система считала с документа. При этом в 60% таких расхождений ошибался именно алгоритм распознавания текста, а не клиент. Традиционные OCR-системы плохо справляются с документами на языках, слабо представленных в обучающих данных, а Sun Finance работает в том числе в регионах с нестандартными алфавитами и форматами удостоверений — компании нужно было обрабатывать 7 типов документов с разными макетами. Отдельную проблему составляло мошенничество: около 10% ежедневных заявок были фиктивными, причём злоумышленники использовали похожие изображения с повторяющимися визуальными паттернами, чтобы обойти базовые фильтры.
| Подход | Точность | Описание |
|---|---|---|
| Claude Sonnet 4 напрямую | 61,8% | Изображение документа отправляется в модель, возврат JSON — мешают протоколы защиты PII |
| Итерация 2 | промежуточная | Команда экспериментировала с улучшением промптов и предобработкой |
| Textract + Rekognition + Claude Sonnet 4 | 90,8% | Многоуровневый конвейер: OCR → резервный OCR → LLM-структурирование |
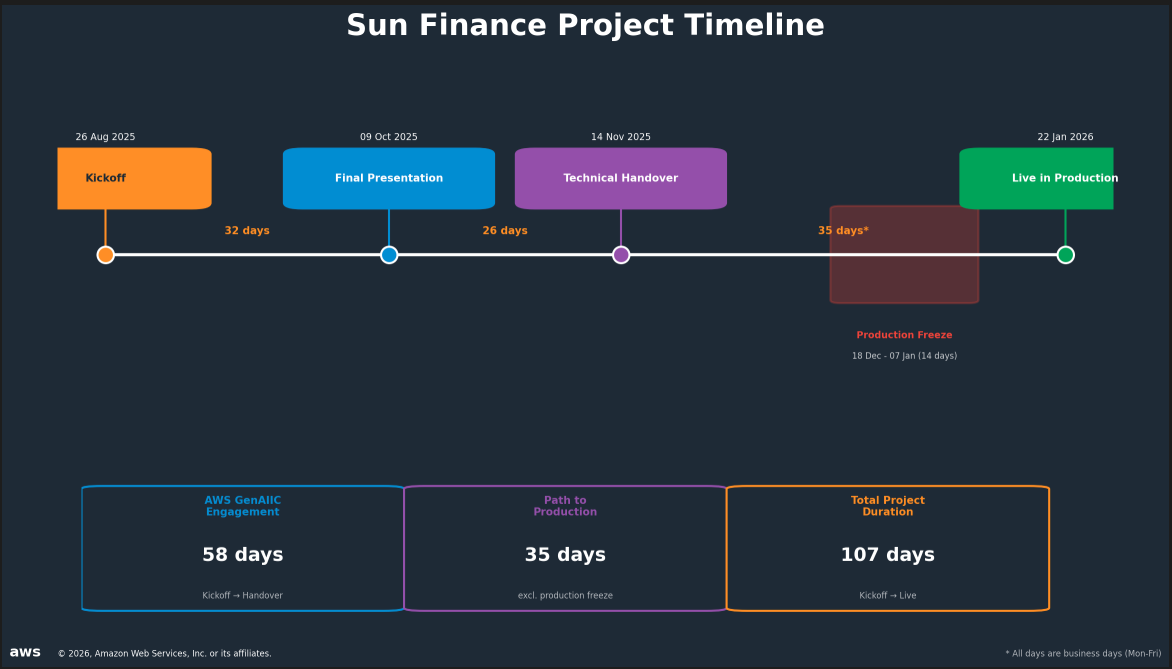
Для перестройки конвейера Sun Finance привлекла AWS Generative AI Innovation Center. Команда провела шестинедельный пилот с сентября по октябрь 2025 года и разработала два независимых решения: систему извлечения данных из документов и систему обнаружения мошенничества. Оба развёрнуты как полностью бессерверная архитектура. Финальное решение передано Sun Finance 14 ноября 2025 года, и уже 22 января 2026 года оно вышло в продакшн — с учётом 14-дневной заморозки релизов в праздничный период.
60% заявок требовали ручной проверки; 80% случаев — из-за ошибок OCR, а не мошенничества.
Система извлечения данных прошла три итерации за четыре недели. Первый подход — отправлять изображение документа напрямую в Claude Sonnet 4 через Amazon Bedrock и просить модель вернуть поля в формате JSON — дал точность 61,8%. Для извлечения номера документа результат оказался ещё хуже: 43%. Причина — встроенные протоколы безопасности модели при работе с персональными данными. Команда не остановилась на этом и итерировала дальше, в итоге придя к многоуровневой схеме: Amazon Textract выполняет первичное OCR-распознавание, при низкой уверенности система переключается на Amazon Rekognition как резервный OCR, а затем Claude Sonnet 4 структурирует извлечённый текст в стандартизированный JSON. Такая комбинация специализированного OCR и LLM для структурирования превзошла каждый из инструментов по отдельности и вывела точность на 90,8%.
Система обнаружения мошенничества построена на векторном поиске по сходству. Когда поступает новая заявка, Lambda-функция запускает параллельный воркфлоу через AWS Step Functions. Первая ветка: Amazon Rekognition маскирует лицо на селфи, Amazon Bedrock Titan Multimodal Embeddings генерирует векторное представление фона изображения, и этот вектор сравнивается с базой известных мошеннических паттернов в Amazon S3 Vectors. Вторая ветка: Claude Sonnet 4 анализирует изображение на артефакты съёмки экрана и следы цифровой обработки. Оба результата объединяются в итоговый fraud score. Подтверждённые мошеннические изображения автоматически добавляются в базу — система обучается на новых случаях без ручного вмешательства.
Экономический эффект оказался существенным: стоимость обработки одного документа снизилась на 91%, время — с потенциальных 20 часов ожидания ручной проверки до менее 5 секунд. Для компании, чья бизнес-модель строится на микрозаймах с тонкой маржой, именно юнит-экономика определяла, в какие рынки можно выходить. Схожие задачи стоят перед большинством финтех-компаний, работающих в развивающихся регионах: традиционные OCR-решения обучены преимущественно на западных документах и латинице, что делает их ненадёжными там, где документооборот устроен иначе.


