
Тестирование ИИ-агентов, которые работают с внешними сервисами, давно остаётся неудобной задачей. Агент может вызывать базы данных, отправлять письма, бронировать рейсы — и каждый такой вызов в тестовой среде несёт реальные последствия. AWS предложила решение в виде ToolSimulator, встроенного в SDK Strands Evals: инструмент перехватывает вызовы зарегистрированных функций и подменяет их ответами, сгенерированными языковой моделью.
Современные ИИ-агенты строятся на концепции tool calling — способности модели не просто генерировать текст, а вызывать внешние функции: API погоды, поисковые сервисы, корпоративные базы данных, MCP-сервисы. Поведение агента напрямую зависит от того, что эти инструменты возвращают. Тестировать такие системы против живых API неудобно по трём причинам: внешние сервисы имеют rate limits и могут быть недоступны; реальные вызовы порождают реальные побочные эффекты; многие инструменты работают с персональными данными, и прогон сотен тест-кейсов создаёт compliance-риски.
Альтернатива в виде статических заглушек (static mocks) тоже не решает проблему полностью. Заглушки требуют постоянного обновления при изменении API и не справляются с многошаговыми сценариями. Классический пример — агент бронирования авиабилетов: сначала он ищет рейсы, затем проверяет статус бронирования. Второй ответ должен зависеть от результата первого вызова. Захардкоженный ответ этого не отражает.
Вместо статических заглушек инструмент генерирует реалистичные ответы на основе схемы и контекста запроса.
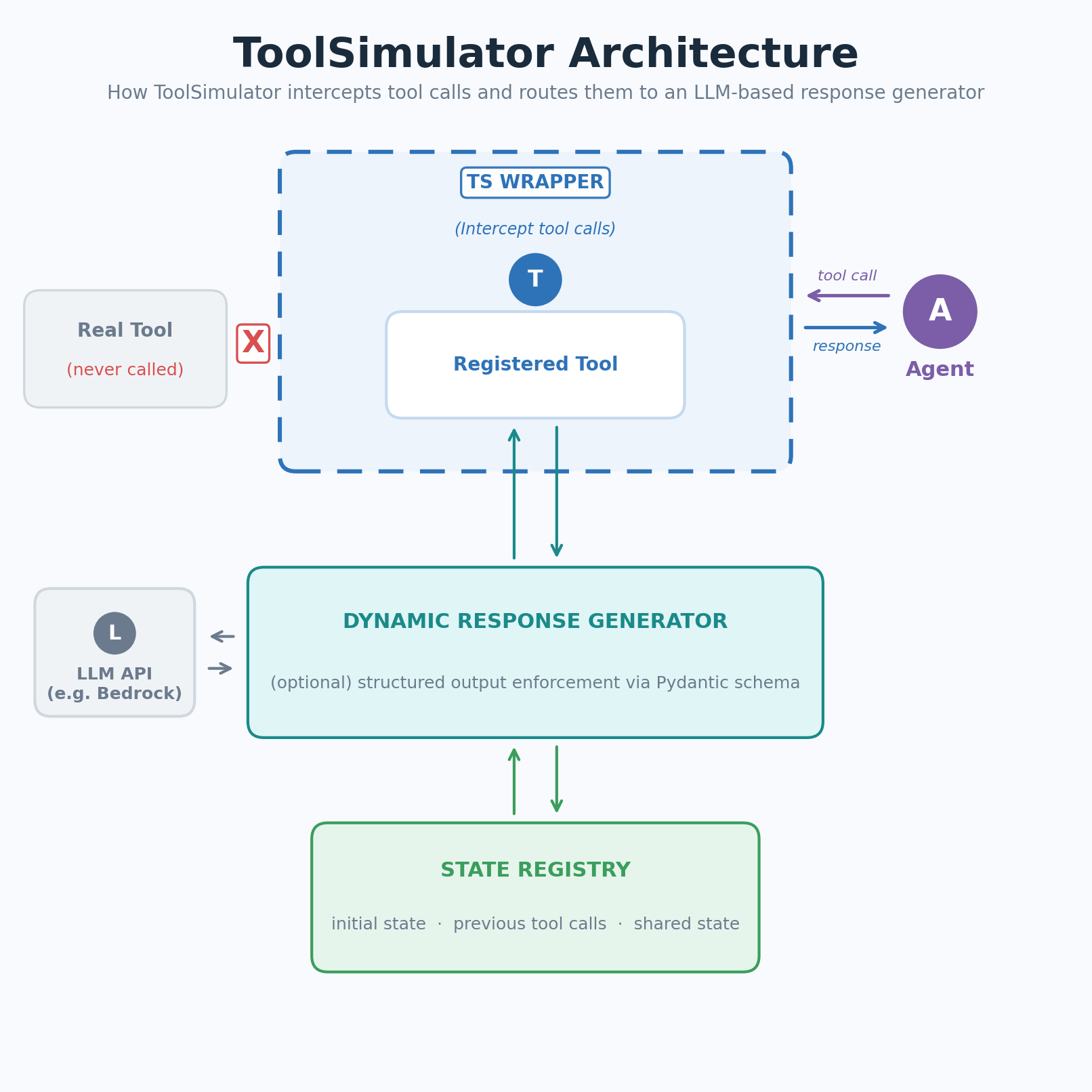
ToolSimulator решает задачу через три механизма. Первый — адаптивная генерация ответов: LLM получает схему инструмента, запрос агента и текущее состояние симуляции, после чего возвращает правдоподобный контекстный ответ. Если агент ищет рейсы Seattle–New York, симулятор вернёт реалистичные варианты с ценами и временем вылета, а не шаблонную заглушку. Второй механизм — общее состояние между инструментами: параметр share_state_id связывает инструменты с единым реестром состояния, так что запись, сделанная одним вызовом, видна следующему. Третий — валидация по Pydantic-схемам: разработчик описывает ожидаемую структуру ответа, и симулятор гарантирует соответствие ещё до того, как данные попадут к агенту.
Рабочий процесс состоит из трёх шагов. Функция-инструмент декорируется через @simulator.tool() — тело функции может оставаться пустым, реальный код не вызывается. Опционально задаётся начальное состояние через initial_state_description на естественном языке: например, «в базе есть рейсы SEA→JFK в 8:00, 12:00 и 18:00, цены от $180 до $420». Затем агент запускается с симулированным инструментом вместо реального.
Strands Evals — относительно новый фреймворк AWS для оценки ИИ-агентов. ToolSimulator логично дополняет его: если раньше разработчики могли оценивать качество ответов агента, то теперь могут делать это в полностью контролируемой среде, не зависящей от доступности внешних сервисов. Схожие подходы существуют в экосистеме LangChain и в инструментах для тестирования агентов на базе OpenAI, однако интеграция симуляции инструментов непосредственно в evaluation pipeline — относительно редкое решение. Для локального запуска AWS-аккаунт не нужен; достаточно Python 3.10 и установленного пакета strands-evals.


