
В августе 2025 года NVIDIA опубликовала Parakeet-TDT-0.6B-v3 — открытую модель автоматического распознавания речи (ASR) под лицензией CC-BY-4.0. Модель охватывает 25 европейских языков, среди которых русский, украинский, немецкий, французский, испанский и ещё двадцать других, и автоматически определяет язык без дополнительной настройки. По данным NVIDIA, в чистых акустических условиях модель достигает 6,34% Word Error Rate (WER), а при сильном шуме (0 дБ SNR) — 11,66% WER. Поддерживается обработка аудиофайлов длиной до трёх часов через режим локального внимания.
Основное техническое отличие Parakeet-TDT от классических ASR-систем — архитектура Token-and-Duration Transducer (TDT). Вместо того чтобы обрабатывать каждый фрейм аудио последовательно, модель одновременно предсказывает текстовые токены и их длительность, что позволяет интеллектуально пропускать паузы и повторяющиеся участки. Результат — скорость инференса на порядки выше реального времени: модель обрабатывает часовую запись значительно быстрее, чем она длится. Именно это свойство делает её привлекательной для задач, где стоимость вычислений критична: архивирование медиатек, анализ записей колл-центров, подготовка обучающих данных для ИИ, генерация субтитров.
| Pricing Model | Hourly Cost (g6.xlarge)* | Cost per Minute of Audio |
|---|---|---|
| On-Demand | ~$0.805 | **$0.00011** |
| Spot Instances | ~$0.374 | **$0.00005** |
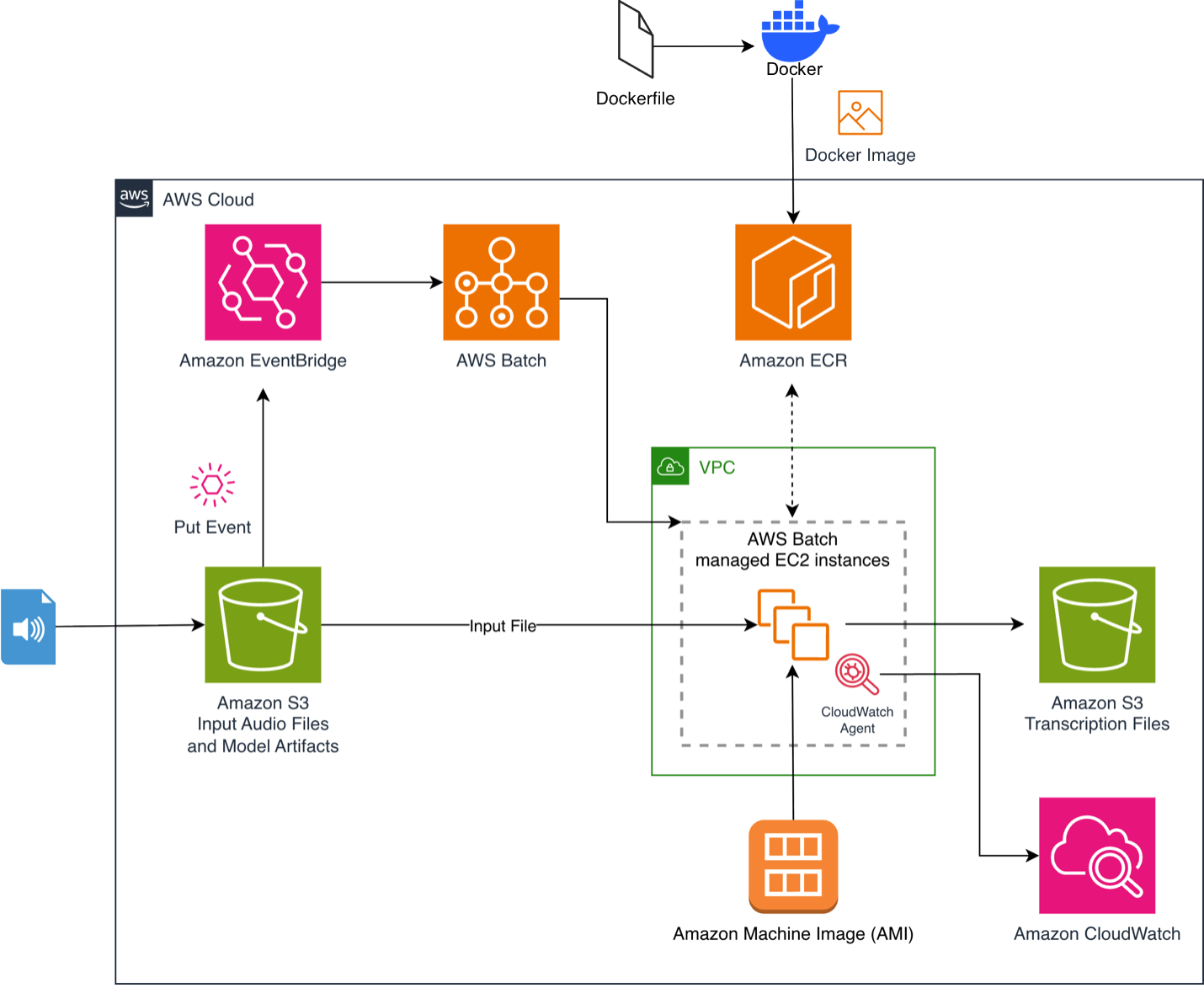
Для развёртывания в облаке AWS инженеры блога Machine Learning предложили событийно-управляемый пайплайн на базе AWS Batch. Схема работает следующим образом: загрузка аудиофайла в бакет Amazon S3 автоматически запускает правило Amazon EventBridge, которое отправляет задание в AWS Batch. Batch поднимает GPU-инстанс, скачивает контейнерный образ с предзагруженной моделью из Amazon ECR и запускает инференс. Готовый транскрипт с временными метками в формате JSON сохраняется в выходной S3-бакет. Когда очередь пуста, среда масштабируется до нуля — плата не начисляется.
Архитектура Token-and-Duration Transducer пропускает тишину и избыточные фрагменты, что даёт скорость обработки на порядки выше реального времени.
По аппаратным требованиям модель достаточно экономична: минимум 4 ГБ VRAM, хотя 8 ГБ обеспечивают лучшую производительность. Авторы рекомендуют инстансы G6 с видеокартами NVIDIA L4 как оптимальные по соотношению цены и скорости для задач инференса. Также поддерживаются G5 (A10G), G4dn (T4), а для максимальной пропускной способности — P5 (H100) и P4 (A100). Дополнительный рычаг снижения затрат — Amazon EC2 Spot Instances: они предоставляют неиспользуемые мощности AWS со скидкой до 90% от цены по требованию. Поскольку задания ASR не хранят состояния между запусками, они хорошо переносят прерывания: AWS Batch автоматически перезапускает задание до двух раз при отзыве Spot-инстанса.
Для сравнения: управляемые ASR-сервисы крупных облачных провайдеров, как правило, тарифицируются поминутно и не зависят от реальной вычислительной нагрузки. При больших объёмах — десятки тысяч часов в месяц — эта модель ценообразования становится главным ограничением масштабирования. Подход с self-hosted моделью на Spot-инстансах переводит расходы в категорию «платишь только за реальные вычисления», что при высоких скоростях TDT-архитектуры даёт кратное снижение итоговой стоимости. Схожую логику ранее применяли для модели Whisper от OpenAI на AWS Inferentia — Parakeet-TDT предлагает аналогичный паттерн, но с многоязычным охватом и более высокой скоростью инференса на GPU.


