
Антивирусный вендор Trend Micro, обслуживающий корпоративных клиентов по всему миру, столкнулся с типичной для enterprise-чат-ботов проблемой: модель не помнит, что происходило в прошлых сессиях, и не знает специфики конкретной организации. Для продукта Trend's Companion — чат-бота, через который клиенты изучают продукты компании в режиме диалога, — это означало размытые, неточные ответы без привязки к реальному контексту заказчика.
Решение строится на трёх компонентах. Amazon Neptune — управляемая графовая база данных AWS — хранит так называемый граф знаний компании: набор сущностей и связей между ними в форме триплетов вида «субъект — предикат — объект». Mem0 — open-source-библиотека для управления памятью ИИ-агентов — отвечает за два слоя: краткосрочный (контекст текущего разговора) и долгосрочный (знания, которые должны сохраняться между сессиями). Amazon Bedrock оркестрирует работу агента, связывая оба хранилища в единый пайплайн.
Процесс создания памяти выглядит так: сообщение пользователя поступает в модель Claude на Amazon Bedrock, которая извлекает из него сущности и потенциальные факты. Они превращаются в векторные эмбеддинги через Bedrock Titan Text Embed и сравниваются с уже имеющимися записями в Amazon OpenSearch Service и Neptune. Найденные совпадения обновляются, переиндексируются и возвращаются в оба хранилища — замкнутый цикл, благодаря которому граф знаний не устаревает.
Mem0 управляет двумя слоями памяти: краткосрочной (текущий диалог) и долгосрочной (знания между сессиями).
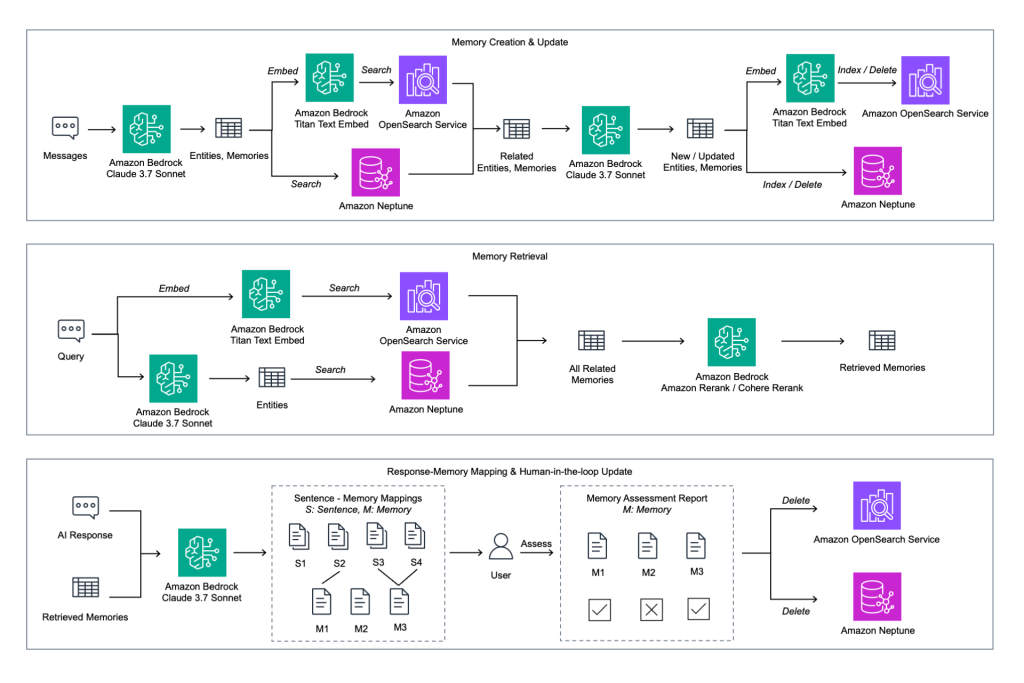
При ответе на запрос система применяет тот же эмбеддинг-пайплайн и ищет одновременно по векторному индексу OpenSearch и по триплетам Neptune. Результаты ранжируются моделями Amazon Bedrock Rerank или Cohere Rerank — это позволяет отдавать предпочтение семантически близким фрагментам из OpenSearch и структурно точным фактам из Neptune. Разница в качестве ответов хорошо видна на примере из документации: без графа на вопрос «Кто признал Хубилая правителем?» модель выдаёт расплывчатое «монгольский правитель, получивший признание разных групп». С графом, где есть триплет (Ильханы, признали, Хубилай), ответ становится конкретным и проверяемым.
Отдельный механизм — human-in-the-loop: после каждого ответа система показывает пользователю, какие именно воспоминания были использованы. Пользователь может одобрить или отклонить каждое из них. Отклонённые факты удаляются из OpenSearch и Neptune, одобренные остаются. Это даёт корпоративным клиентам прямой контроль над тем, что знает их ИИ-ассистент, — критически важное свойство для enterprise-среды, где ошибочный факт в базе знаний может повлечь репутационные или операционные последствия.
Подобный подход — комбинация графовой базы данных с векторным поиском и LLM — называется Graph RAG (Retrieval-Augmented Generation с графом). В отличие от классического RAG, где поиск ведётся только по семантической близости текстовых фрагментов, граф позволяет явно кодировать отношения между объектами и делать многошаговые выводы. Microsoft, Neo4j и ряд других компаний развивают схожие подходы, однако интеграция с управляемыми облачными сервисами AWS делает архитектуру Trend Micro относительно доступной для воспроизведения. Исходный код опубликован на GitHub; проект по-прежнему проходит оценку и настройку перед полноценным развёртыванием.


