Долгое время масштабирование фундаментальных моделей означало одно: больше вычислений на предобучении — выше качество. Эту интуицию подкрепляла работа Kaplan et al. (2020), зафиксировавшая степенные зависимости между потерями и размером модели, объёмом данных и объёмом вычислений. Сегодня картина сложнее: NVIDIA описывает три отдельных scaling-режима — предобучение, постобучение и вычисления во время инференса (так называемое test-time compute: «долгое мышление», поиск с верификацией, стратегии множественной выборки). Каждый из них предъявляет схожие требования к инфраструктуре, но по-разному нагружает её компоненты.
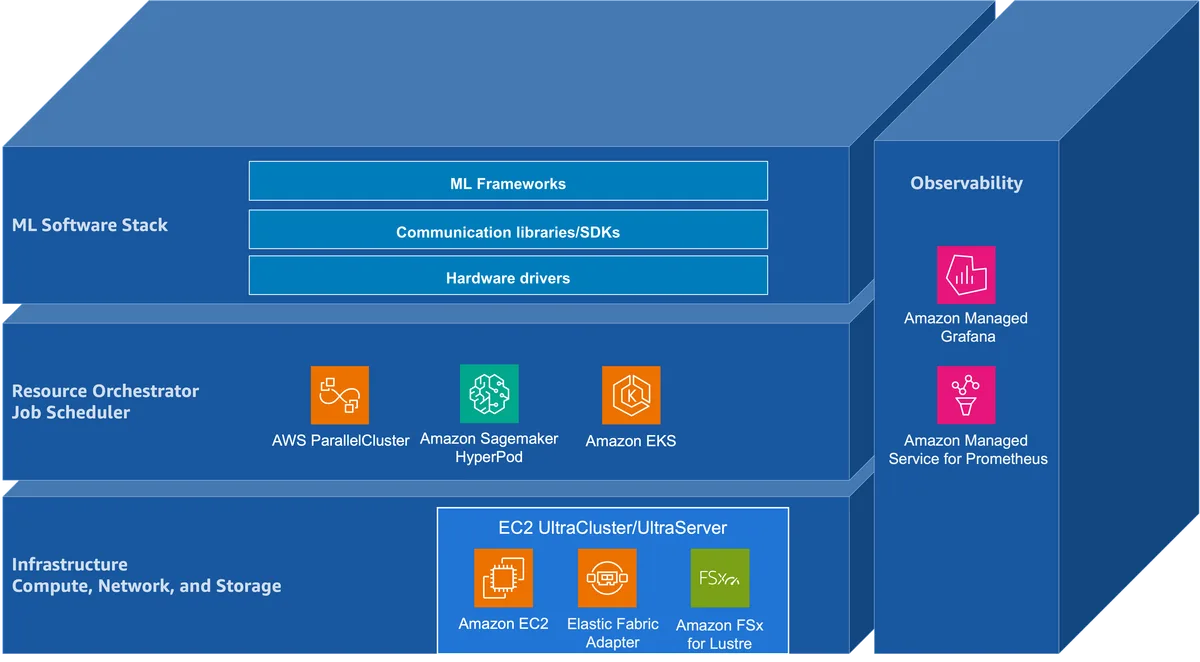
В техническом разборе, опубликованном на Hugging Face Blog, описывается, как AWS реализует эту инфраструктуру. В основе — три взаимосвязанных слоя: ускоренные вычисления с большой памятью устройства, высокополосная низколатентная сеть для коллективных операций и распределённое хранилище для данных и чекпоинтов. Поверх них работает стандартный открытый стек: Slurm или Kubernetes для управления ресурсами кластера, PyTorch или JAX для распределённого обучения, Prometheus и Grafana для мониторинга.
| GPU | BF16/FP16 пик (плотный) | FP8 пик (плотный) | FP4 пик (плотный) | Память HBM | Полоса HBM |
|---|---|---|---|---|---|
| H100 (SXM) | 0,99 PFLOPS | 1,98 PFLOPS | — | 80 ГБ HBM3 | 3,35 ТБ/с |
| H200 (SXM) | 0,99 PFLOPS | 1,98 PFLOPS | — | 141 ГБ HBM3e | 4,8 ТБ/с |
| B200 (HGX, на GPU) | 2,25 PFLOPS | 4,5 PFLOPS | 9 PFLOPS | 180 ГБ HBM3e | 8 ТБ/с |
| B300 (HGX, на GPU) | 2,25 PFLOPS | 4,5 PFLOPS | 13,5 PFLOPS | 288 ГБ HBM3e | 8 ТБ/с |
На стороне вычислений AWS предлагает несколько поколений инстансов. Семейство P5 включает p5.48xlarge с восемью NVIDIA H100 (640 ГБ HBM3 суммарно) и p5e/p5en.48xlarge с H200 (1128 ГБ HBM3e). Семейство P6 переходит на архитектуру Blackwell: p6-b200.48xlarge несёт восемь GPU B200 с 1440 ГБ HBM3e, а p6-b300.48xlarge — восемь B300 с 2100 ГБ HBM3e. По пиковой производительности на одном GPU B300 даёт 2,25 PFLOPS для BF16/FP16, 4,5 PFLOPS для FP8 и 13,5 PFLOPS для FP4 (плотные операции без sparsity), что примерно вдвое превышает показатели H100.
AWS предлагает инстансы P5 с H100/H200 и P6 с Blackwell B200/B300; у B300 — 288 ГБ HBM3e и пропускная способность 8 ТБ/с на GPU.

Сеть разделена на два уровня. Внутри узла GPU соединены через NVLink/NVSwitch: у P5 это четвёртое поколение NVLink с агрегатной полосой 7,2 ТБ/с, у P6 — пятое поколение с 14,4 ТБ/с. Такая связность позволяет выполнять коллективные операции (all-reduce, all-gather) без выхода в хостовую сеть. Между узлами работает Elastic Fabric Adapter (EFA) — сетевой интерфейс с обходом ядра ОС через протокол SRD и Libfabric API. Это снижает задержку и повышает пропускную способность для межузловых коллективов. P5 оснащён EFAv2 с агрегатной полосой 400 ГБ/с, P6 с B300 — EFAv4 с 800 ГБ/с.
Авторы подчёркивают принципиальный момент: при масштабировании время шага обучения всё чаще определяется не сырой вычислительной мощностью, а пропускной способностью коллективных коммуникаций и скоростью перемещения данных в памяти. Это делает явный учёт полосы пропускания — как внутри узла, так и между узлами — обязательным при проектировании кластера, а не опциональным.
Опубликованный материал позиционируется как введение в серию. Последующие части обещают разобрать оркестрацию ресурсов, ML-фреймворки и наблюдаемость. Для отрасли это означает появление структурированного публичного руководства по стыковке открытого программного стека с конкретной облачной аппаратурой — информации, которая прежде существовала преимущественно в виде разрозненной документации и внутренних знаний команд.


