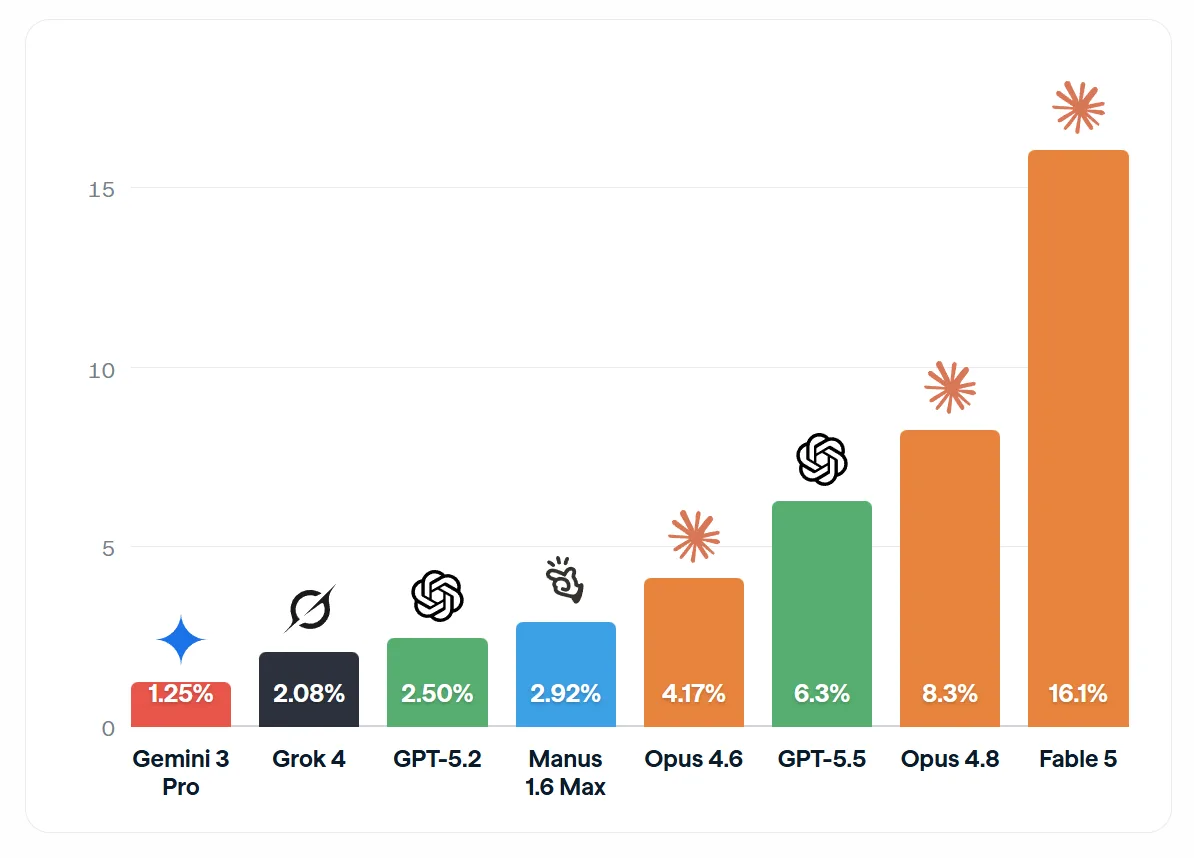
Исследователи из Центра безопасности ИИ (CAIS) совместно с Scale Labs представили обновлённые результаты Remote Labor Index (RLI) — бенчмарка, измеряющего долю фриланс-проектов, которые ИИ-агенты могут выполнить на профессиональном уровне. За восемь месяцев лучший показатель автоматизации вырос с 2,5% до 16,1%, что более чем в шесть раз.
RLI оценивает 240 проектов общей стоимостью $144 тыс., взятых у 358 верифицированных фрилансеров в таких областях, как 3D-моделирование, архитектура, графический дизайн, видео и анимация, аудио, анализ данных и веб-приложения. Каждый результат оценивается экспертами-людьми по сравнению с эталоном, созданным профессиональным исполнителем. Лидером стал агент на базе модели Fable 5, достигший 16,1% — примерно вдвое больше, чем у Opus 4.8 (8,3%) и GPT-5.5 (6,3%). Предыдущий рекорд в 4,17% принадлежал Opus 4.6 на фреймворке Claude Cowork.
| Модель / Агент | Уровень автоматизации |
|---|---|
| Fable 5 | 16,1% |
| Opus 4.8 | 8,3% |
| GPT-5.5 | 6,3% |
| Opus 4.6 (Claude Cowork) | 4,17% |
| Gemini 3 Pro | 1,25% |
Однако к результату Fable 5 стоит отнестись с осторожностью: из-за ограничений доступа, введённых правительством США, удалось оценить только 218 из 240 проектов. Даже в худшем случае, когда Fable 5 провалил все пропущенные задачи, его показатель остался бы на уровне 14,6%, что всё равно выше конкурентов. Интересно, что прогресс не привязан к датам релиза: относительно новый Gemini 3 Pro показал лишь 1,25%, отстав от гораздо более старых систем.
Бенчмарк включает 240 проектов на $144 тыс. в 8 категориях фриланса.

Попытка заменить человеческих оценщиков ИИ не удалась. ИИ-судьи существенно завышали оценки — для GPT-5.5 почти в три раза, для Opus 4.8 — в два с половиной. Причина в том, что для справедливой оценки требуется открывать файлы в профессиональных программах и работать с ними, а это как раз то, с чем современные ИИ-агенты справляются хуже всего. Например, в одном из тестов GPT-5.5 создал привлекательный рендер с помощью генератора изображений, но его 3D-модель осталась некачественной — мошенничество можно обнаружить, только открыв модель.
Для тестирования агентов исследователи использовали виртуальную машину Linux с более чем 30 профессиональными приложениями (Blender, GIMP, Audacity) и до 24 часов вычислительного времени на проект. Агенты работали с инструментами вроде Claude Code и Codex CLI, дополненными возможностью управлять графическими программами. Также применялся цикл критики: второй агент проверял результат как требовательный клиент, после чего первый дорабатывал работу.
Несмотря на быстрый прогресс, до профессионального уровня ещё далеко. Ни один из трёх показанных примеров Fable 5 не прошёл бы как готовая работа. Авторы подчёркивают, что рост автоматизации напрямую отражает ускорение автоматизации удалённой работы, но пока ИИ не может заменить человека в большинстве задач.


