
Google выложила в открытый доступ DiffusionGemma — экспериментальную языковую модель, построенную на диффузионном принципе генерации текста. По качеству ответов она сопоставима с другими моделями четвёртого поколения Gemma, но работает примерно в четыре раза быстрее. Модель доступна на Hugging Face под лицензией Apache 2.0.
Чтобы понять, почему это интересно, нужно разобраться в разнице подходов. Большинство современных языковых моделей — авторегрессионные: они генерируют текст токен за токеном, слева направо, и каждый следующий токен зависит от предыдущих. Диффузионные модели работают иначе: они начинают с «шума» — случайного набора токенов — и итеративно уточняют весь блок сразу, предсказывая множество позиций параллельно. Именно эта параллельность и даёт выигрыш в скорости.
| Характеристика | Авторегрессионная модель | DiffusionGemma |
|---|---|---|
| Принцип генерации | Токен за токеном, последовательно | Весь блок параллельно, итеративное уточнение |
| Скорость (локально) | Базовая | ~4× быстрее |
| Эффективность в облаке | Высокая (батчинг + HBM) | Ниже из-за параллельных издержек |
| Ошибки в тексте | Локальные, не ломают контекст | Ошибка в блоке может обнулить весь фрагмент |
| Короткие ответы | Эффективны | Избыточная параллельная работа |
| Лицензия | Apache 2.0 (Gemma 4) | Apache 2.0 |
Для локального запуска на потребительском железе диффузионный подход особенно выгоден. В облаке авторегрессионные модели компенсируют свою последовательность за счёт батчинга — одновременной обработки запросов тысяч пользователей и высокоскоростной памяти HBM. На локальном устройстве такой возможности нет: память медленнее, вычислительные циклы простаивают между токенами. Диффузионная архитектура лучше утилизирует доступные ресурсы именно в таких условиях.
Модель доступна под лицензией Apache 2.0 на Hugging Face; веса можно скачать уже сейчас.
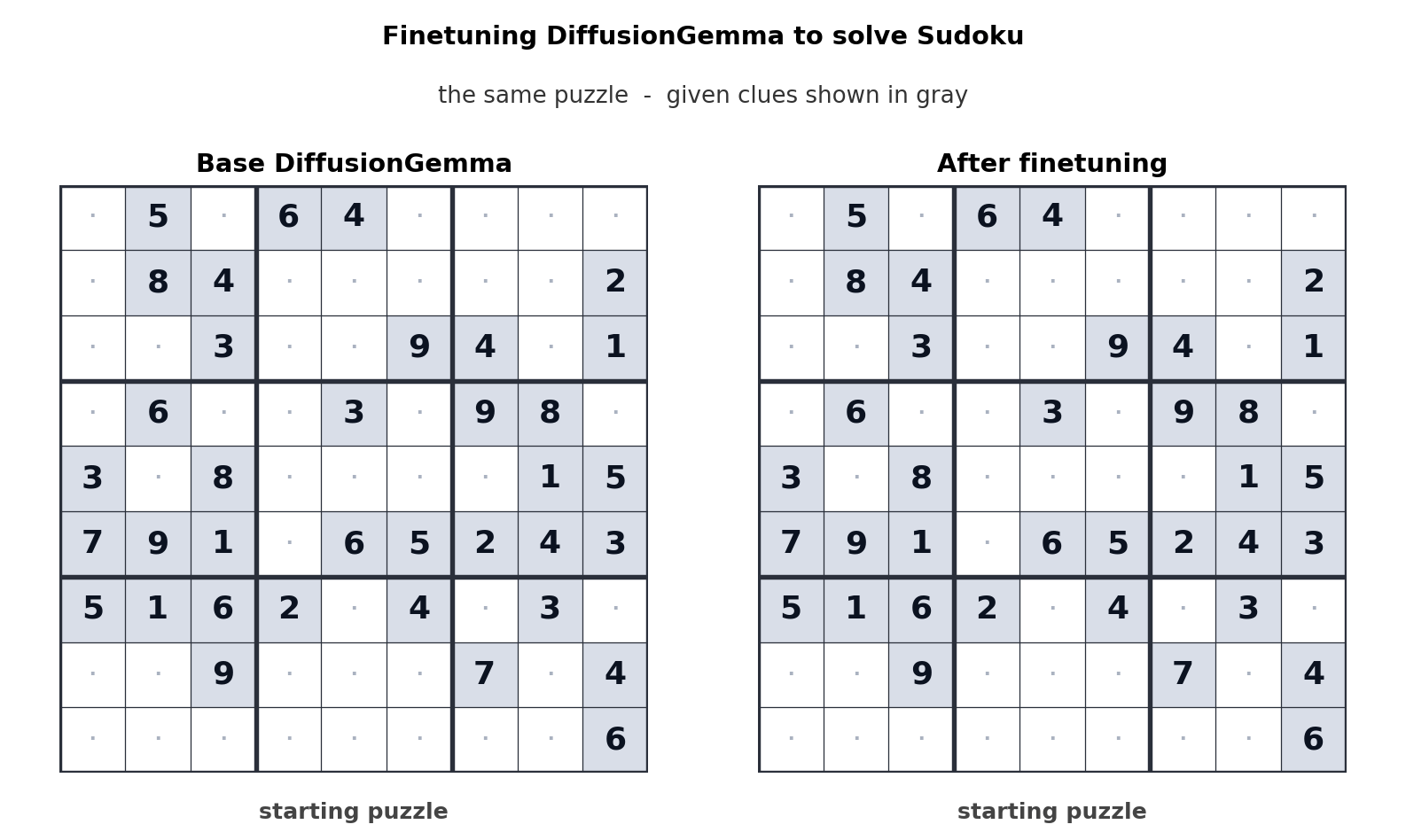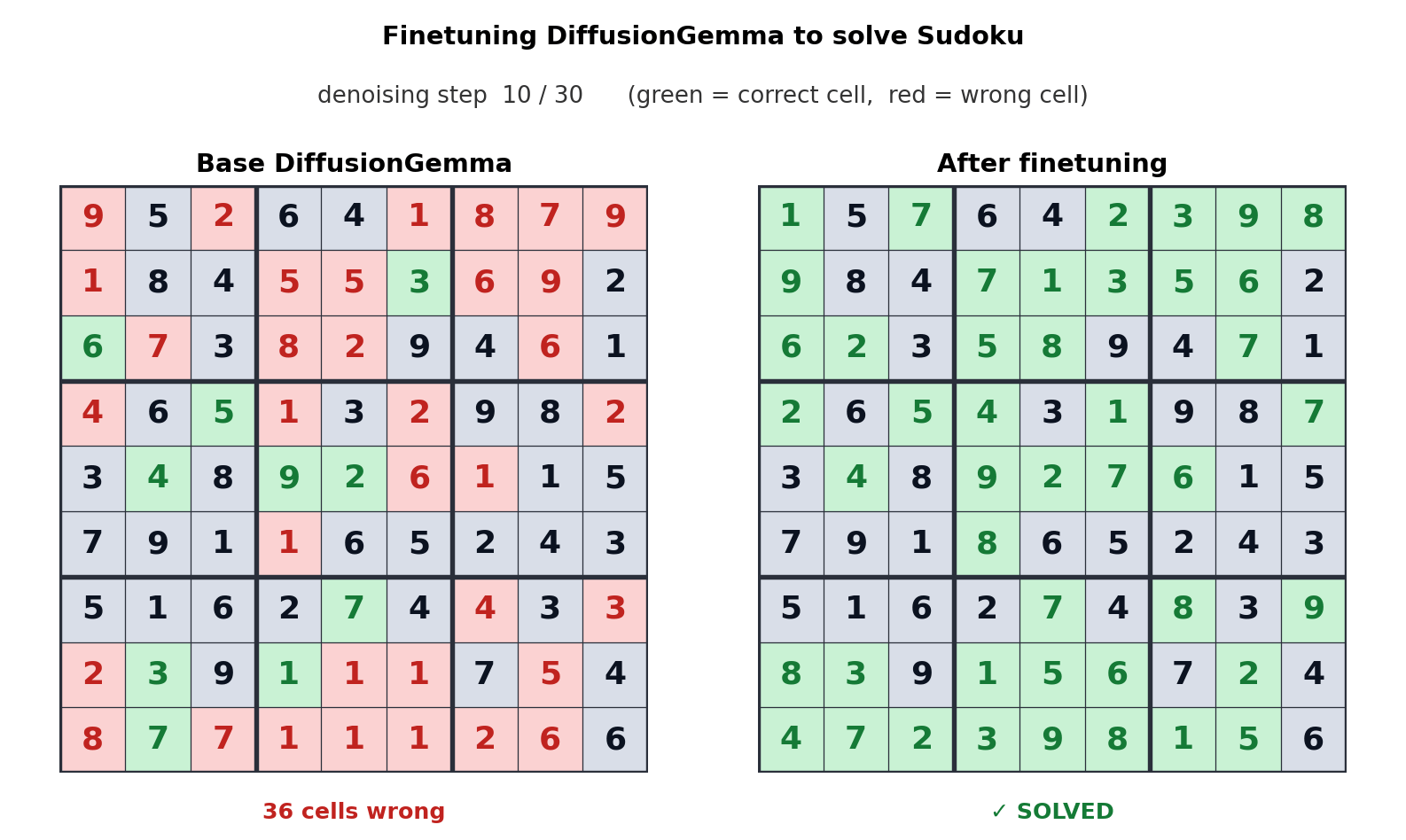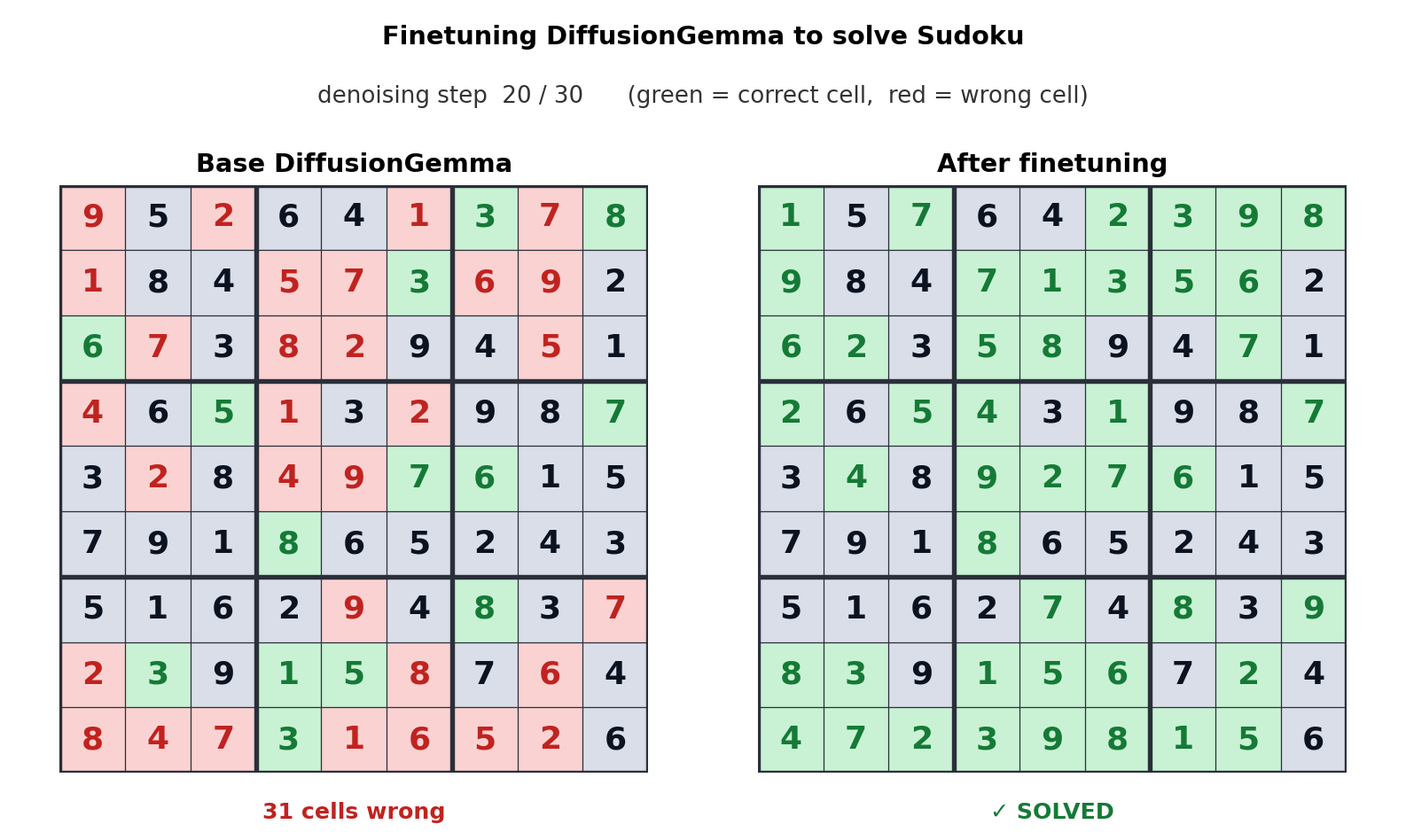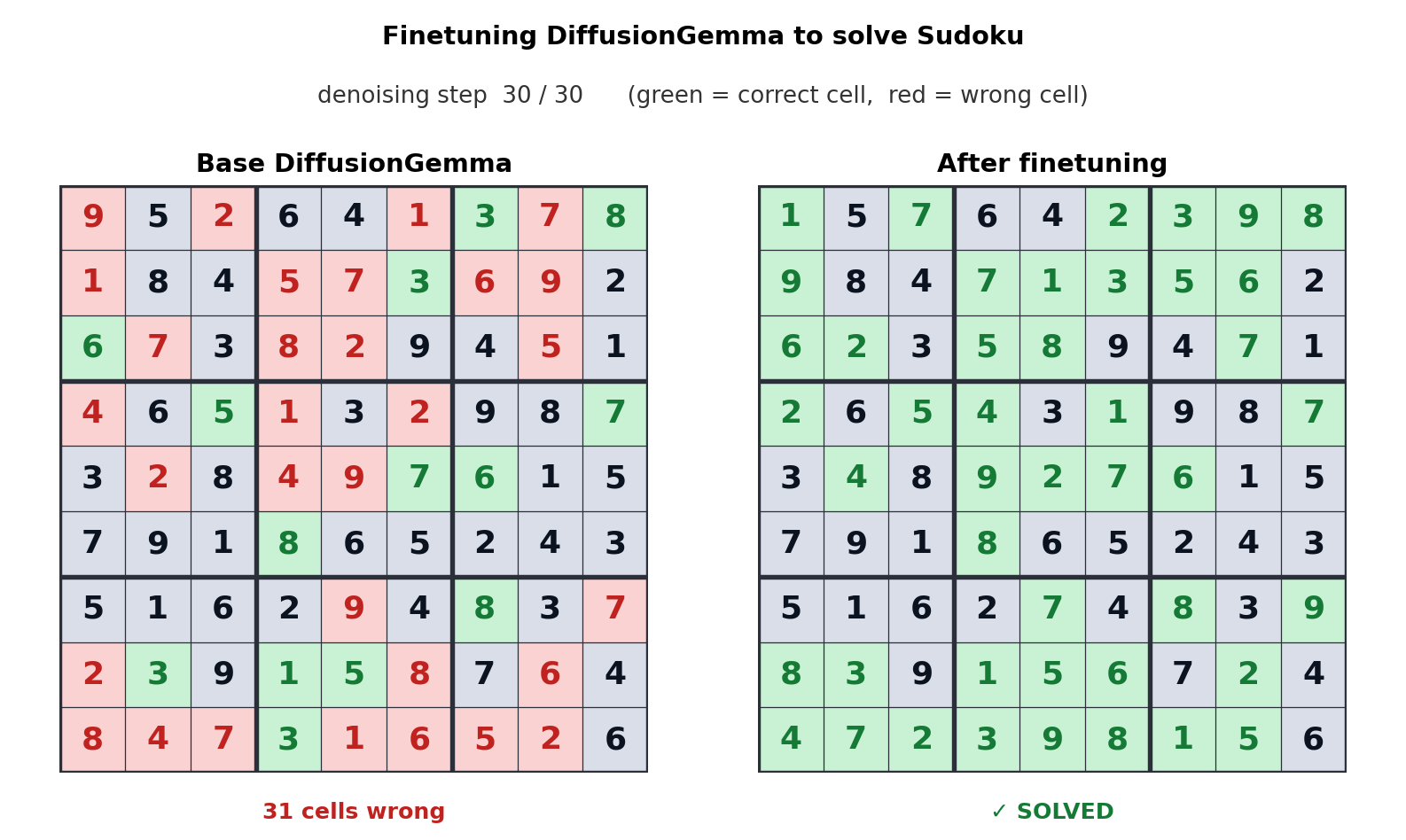
Однако у диффузии в тексте есть принципиальные ограничения, которые объясняют, почему Google не переводит на этот подход основные облачные модели Gemini. В отличие от изображений, где один неудачно предсказанный пиксель не портит картину, язык дискретен: одна ошибка в блоке токенов может сделать весь фрагмент бессмысленным и потребовать повторной генерации. Кроме того, диффузионные модели неэффективны при коротких ответах — они выполняют столько же параллельной работы для пяти токенов, сколько для пятисот, тогда как авторегрессионная модель просто остановится после пяти шагов.
Параллельно Google развивает ещё один способ ускорения — Multi-Token Prediction (MTP): специальные «черновики», которые используют простаивающие вычислительные циклы для предсказания нескольких токенов вперёд. Но даже MTP-версии Gemma уступают DiffusionGemma по скорости.
Модель оптимизирована совместно с Nvidia и поддерживает широкий спектр конфигураций: потребительские видеокарты RTX с квантизацией, серверные H100 и платформу DGX Spark. Google подчёркивает экспериментальный статус DiffusionGemma, однако открытая лицензия и доступность весов делают её доступной для исследователей и разработчиков уже сейчас. Для отрасли это сигнал: диффузионный подход к генерации текста перестаёт быть академической экзотикой и превращается в практический инструмент для edge-устройств и локального инференса.

