Тонкая настройка моделей Mixture-of-Experts (MoE) — одна из самых ресурсоёмких задач в современном машинном обучении. Маршрутизация токенов между сотнями экспертов, слияние матричных умножений, распределение весов по GPU и наложение коммуникаций на вычисления требуют инфраструктуры, выходящей за рамки возможностей универсальных библиотек. Вышедшая недавно пятая версия Hugging Face Transformers решила часть проблем, добавив встроенную поддержку MoE: экспертные бэкенды, динамическую загрузку весов и планы тензорного параллелизма для распределённого исполнения. Однако вопросы эффективного распараллеливания экспертов и перекрытия коммуникации с вычислениями оставались открытыми.
NVIDIA NeMo AutoModel — открытая библиотека, входящая в фреймворк NeMo, — восполняет эти пробелы. Она наследуется от AutoModelForCausalLM из Transformers v5 и добавляет Expert Parallelism (EP), fused all-to-all диспетчеризацию через DeepEP и оптимизированные ядра TransformerEngine. DeepEP — ключевой компонент, отсутствующий в v5: он позволяет перекрывать коммуникацию между экспертами с вычислительными операциями, что критически снижает время простоя GPU. При этом NeMo AutoModel использует механизм обратимого преобразования весов v5, поэтому фокусируется на универсальных оптимизациях, а не на адаптации под каждый чекпоинт. Сохранённые через save_pretrained() чекпоинты остаются стандартными для Hugging Face и совместимы с инструментами вроде vLLM и SGLang.
| Parameter | Value |
|---|---|
| Hardware | 16x H100 80GB (128 GPUs) |
| Expert Parallelism | EP=64 |
| Local batch size | 2 |
| Sequence length | 4,096 |
| Features | MTP, activation checkpointing, fused linear cross-entropy |
| Kernels | DeepEP dispatch + torch_mm experts + TransformerEngine |
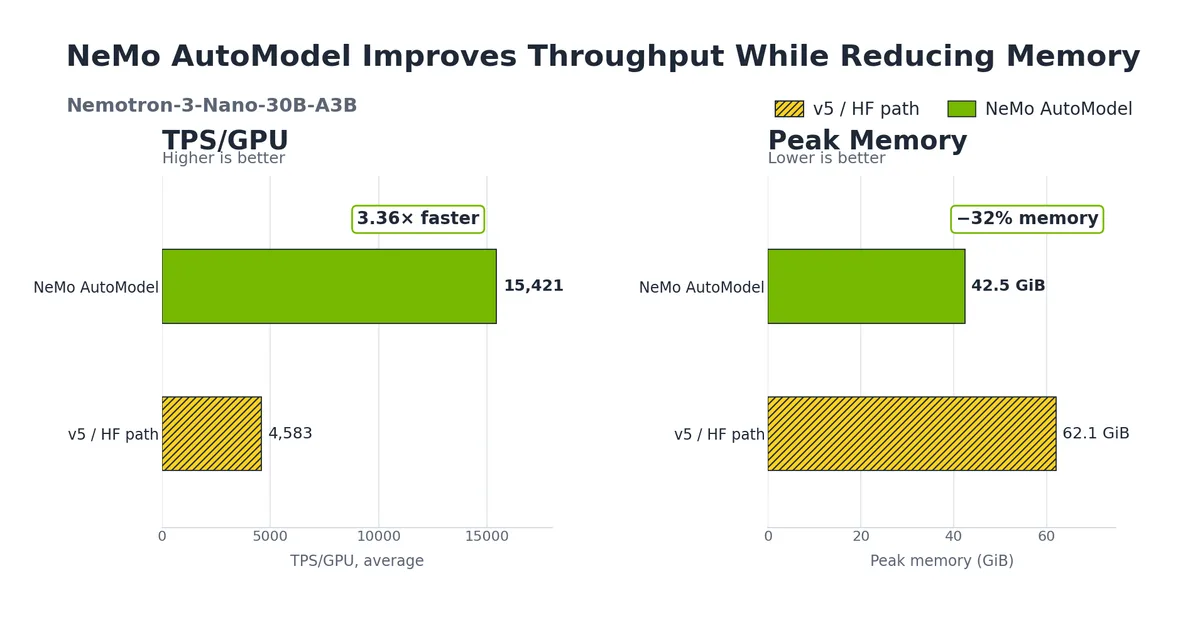
Измеренные авторами ускорения впечатляют: по сравнению с нативным Transformers v5 тонкая настройка MoE-моделей с NeMo AutoModel даёт рост пропускной способности в 3,4–3,7 раза и снижение потребления памяти GPU на 29–32%. Тестирование проводилось в двух режимах: полная тонкая настройка масштабной модели Nemotron 3 Ultra на 550 млрд параметров (16 узлов) и обучение двух 30-миллиардных MoE-моделей на одном узле. Для одноузловых конфигураций, таких как Qwen3-30B-A3B и Nemotron 3 Nano 30B A3B, выигрыш в скорости и памяти особенно заметен.
Ускорение тонкой настройки MoE-моделей достигает 3,4–3,7 раза при снижении потребления памяти на 29–32%.

Важно, что для перехода на NeMo AutoModel достаточно изменить одну строку импорта: вместо from transformers import AutoModelForCausalLM используется from nemo_automodel import NeMoAutoModelForCausalLM. Весь остальной код, включая работу с токенизатором, датасетами и циклами обучения, остаётся без изменений. Для масштабирования на несколько GPU добавляется конфигурация распределённого обучения (device_mesh), но API from_pretrained() сохраняется. Это позволяет сообществу open-source легко интегрировать ускорение без переписывания пайплайнов.
Ограничение подхода — необходимость ручной оптимизации под конкретные архитектуры для достижения максимальной производительности. NeMo AutoModel включает готовые реализации для Qwen3, Nemotron, GPT-OSS и DeepSeek V3. Для других архитектур используется запасной вариант vanilla HF с применением патчей ядер Liger. Тем не менее, общая прирост производительности даже на fallback-режиме остаётся существенным благодаря Expert Parallelism и DeepEP. В перспективе ожидается расширение списка поддерживаемых архитектур за счёт сообщества.


