
Запуск языковых моделей в продакшене ставит перед инженерами задачу, которой не было при работе с классическим ПО: стандартные метрики доступности и задержки не говорят ничего о том, правильно ли модель отвечает. Эндпоинт может возвращать ответы за 200 мс с нулевым процентом ошибок — и при этом систематически генерировать небезопасный или фактически неверный контент. AWS Machine Learning Blog опубликовал детальное описание архитектуры, которая закрывает этот пробел для SageMaker ИИ Inference.
Решение разделяет мониторинг на два независимых измерения. Первое — количественное: операционное здоровье инфраструктуры, то есть пропускная способность, утилизация GPU и CPU, задержки, распределение запросов между моделями и стоимость вычислений. Второе — качественное: оценка самих ответов модели по composite quality score, safety score и задержке оценки. Оба потока метрик хранятся в Amazon CloudWatch, но в разных пространствах имён: `/aws/sagemaker/InferenceComponents/<model-name>` для операционных данных и `/aws/sagemaker/inference-quality/<model-name>` для качественных сигналов. Такое разделение позволяет настраивать алерты и дашборды независимо, не смешивая разнородные данные.
| Пространство имён CloudWatch | Что фиксирует | Назначение |
|---|---|---|
| /aws/sagemaker/InferenceComponents/<model-name> | Операционные метрики: уровень инстанса, контейнера и GPU | Видимость в количество вызовов, задержки, ошибки, утилизацию GPU/CPU по каждой модели |
| /aws/sagemaker/inference-quality/<model-name> | Качественные метрики: composite quality score, safety score, evaluation latency | Сигналы качества ответов LLM, отделённые от операционных метрик |
Ключевая особенность архитектуры — поддержка inference components, механизма SageMaker, который позволяет размещать несколько моделей на одном эндпоинте с изолированными политиками масштабирования и раздельной атрибуцией метрик. В описанном примере на одном эндпоинте сосуществуют gpt-oss-20b и Qwen2.5-7B-Instruct. Это типичный сценарий для A/B-тестирования моделей или постепенного перехода с одной версии на другую без простоя. Без per-model метрик понять, какая из моделей потребляет больше GPU-памяти или генерирует больше ошибок, было бы невозможно.
Метрики разделены на два пространства имён CloudWatch: операционные (GPU, CPU, задержки) и качественные (composite quality score, safety score).
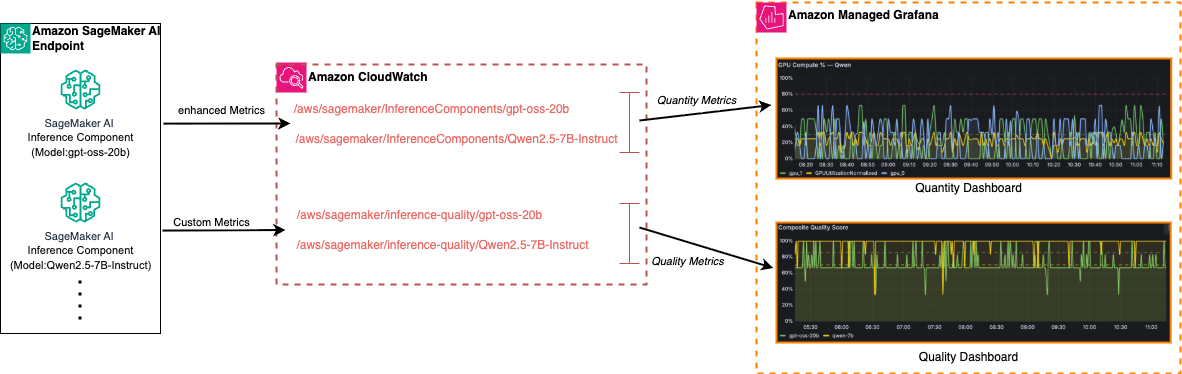
Визуализация строится в Amazon Managed Grafana с CloudWatch в роли нативного источника данных. Количественный дашборд включает три группы панелей: динамика задержек и количества вызовов в разрезе моделей; загрузка GPU по вычислениям и памяти с кросс-модельным сравнением; обзор кластера с соотношением занятых и свободных GPU, числом инстансов и стоимостью каждой модели в час. Качественный дашборд отображает composite quality score, safety score и evaluation latency в сравнении между моделями — что позволяет замечать деградацию качества до того, как она становится заметна пользователям.
Подход отражает более широкую тенденцию в MLOps: команды всё чаще строят LLM-мониторинг поэтапно. Сначала закрывают базовые операционные метрики, затем добавляют сэмплирование и оценку качества ответов, и только после этого настраивают комбинированные пороговые алерты. Без качественного измерения дрейф модели — постепенное ухудшение ответов при смещении входных данных — остаётся невидимым вплоть до жалоб пользователей. Описанная архитектура позволяет коррелировать оба сигнала: например, выяснить, не связан ли рост safety-нарушений с пиками нагрузки на GPU, когда модель работает в условиях memory pressure.


