
Azercell Telecom LLC, крупнейший оператор связи Азербайджана, совместно с AWS Generative ИИ Innovation Center за шесть недель разработала производственный фреймворк для обучения большой языковой модели (LLM) на азербайджанском языке. Решение построено на Amazon SageMaker ИИ и включает три последовательных этапа: создание эффективного токенизатора, продолженное предобучение (CPT) базовой модели Llama 3.2 1B и тонкую настройку с помощью LoRA. Ключевые метрики: 23% рост пропускной способности обучения и 58% снижение пикового потребления памяти GPU благодаря оптимизациям на уровне ядра (Liger Kernel).
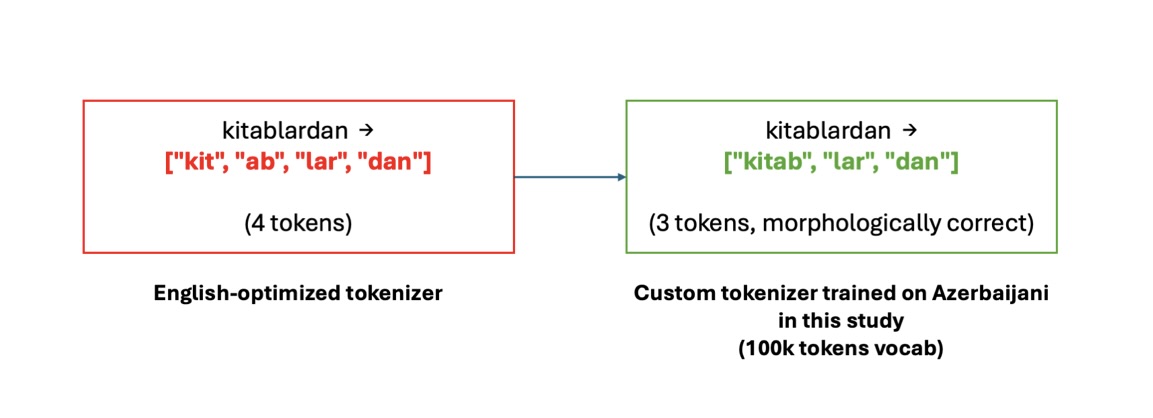
Основной вызов — морфологическая сложность азербайджанского языка. В таких языках одно слово может передавать значение, которое в английском требует нескольких слов. Стандартные токенизаторы, оптимизированные под английский, дробят длинные азербайджанские слова на множество токенов, снижая полезный объём текста в окне контекста. Для решения этой проблемы команда обучила кастомный токенизатор на основе Byte-Level Byte-Pair Encoding (BBPE), который обрабатывает азербайджанские символы напрямую из байтов. Эксперименты со словарём от 50 000 до 100 000 токенов показали, что оптимальный размер — 100 000 токенов — даёт вдвое меньше токенов на слово по сравнению с базовым английским токенизатором.
| Этап | Описание | Ключевой артефакт |
|---|---|---|
| Токенизация | Обучение кастомного BBPE-токенизатора на азербайджанском тексте | Токенизатор с 100 тыс. токенов, 2× меньше токенов на слово |
| Продолженное предобучение (CPT) | Адаптация Llama 3.2 1B к азербайджанскому языку с Liger Kernel | Предобученная модель с 23% ростом пропускной способности |
| Тонкая настройка (LoRA) | Преобразование модели в ассистент для диалога | Модель, готовая к чат-сценариям |
Фреймворк разбит на три автономных этапа. На первом этапе разрабатывается токенизатор, который используется во всех последующих шагах. На втором этапе — продолженное предобучение (CPT) на азербайджанских данных с применением распределённого обучения и Liger Kernel. Несмотря на то что для модели 1B масштаба распределённое обучение не обязательно, оно закладывает основу для будущего масштабирования. На третьем этапе применяется LoRA (Low-Rank Adaptation) — метод параметро-эффективной тонкой настройки, который значительно сокращает количество обучаемых параметров. Все этапы запускаются как Amazon SageMaker ИИ training jobs, которые выделяют ресурсы только на время выполнения и автоматически завершаются, исключая затраты на простаивающие кластеры.
Кастомный токенизатор на основе BBPE сократил количество токенов на слово вдвое по сравнению с базовым.
Разработанный подход особенно ценен для языков с ограниченными данными и сложной морфологией — таких как азербайджанский, где нет готовых рецептов эффективного обучения LLM. Предложенная архитектура модульна: улучшения токенизатора передаются всем последующим этапам, а конфигурация CPT может быть перенесена на новые задачи тонкой настройки. Для Azercell первоочередной сценарий — создание чат-бота для клиентов телеком-оператора, но методология применима и в других отраслях.


