
BoltzGen — это диффузионная модель, которая генерирует структуры белков и пептидов, способных связываться с заданными биомолекулярными мишенями. Процесс дизайна включает несколько этапов: генерация основной цепи (backbone), обратное сворачивание (inverse folding) для подбора аминокислотных последовательностей, валидация структуры с помощью Boltz2 и ранжирование кандидатов. Каждый из этих этапов требует использования GPU-вычислений, а типичная кампания включает сотни и тысячи образцов. Это создает значительную операционную нагрузку: нужно выделять инстансы, передавать данные между шагами, отслеживать затраты и восстанавливаться после сбоев.
Amazon SageMaker ИИ автоматизирует этот жизненный цикл: после отправки задания платформа самостоятельно выделяет GPU-инстанс, запускает в нем контейнер с BoltzGen, сохраняет результаты в S3 и освобождает ресурсы. Биллинг посекундный, поэтому нет затрат на простой. По данным из репозитория, кампания из 1000 образцов на 4-GPU инстансе ml.g5.12xlarge занимает около 375 часов. Для более коротких экспериментов, например двухчасовой прогон на ml.g4dn.xlarge, стоимость составит примерно $1,50.
| Режим | Описание | Когда использовать |
|---|---|---|
| Processing Jobs | Прямое пакетное выполнение, минимальное время настройки | Быстрые эксперименты, тестирование спецификаций |
| Pipelines | Оркестрованный 5-шаговый конвейер с кэшированием и масштабированием | Производственные рабочие нагрузки, итеративная работа |
Реализация поддерживает два режима выполнения. Первый — SageMaker Processing Jobs: прямое пакетное выполнение для быстрых экспериментов, когда требуется минимизировать время настройки. Второй — SageMaker Pipelines: оркестрованный пятишаговый конвейер с кэшированием результатов на 7 дней в S3. Это особенно важно для итеративной работы: шаг генерации, на который приходится около 90% вычислительных затрат, не перезапускается при изменении параметров фильтрации. Каждый шаг (дизайн, обратное сворачивание, фолдинг, анализ, фильтрация) можно масштабировать независимо.
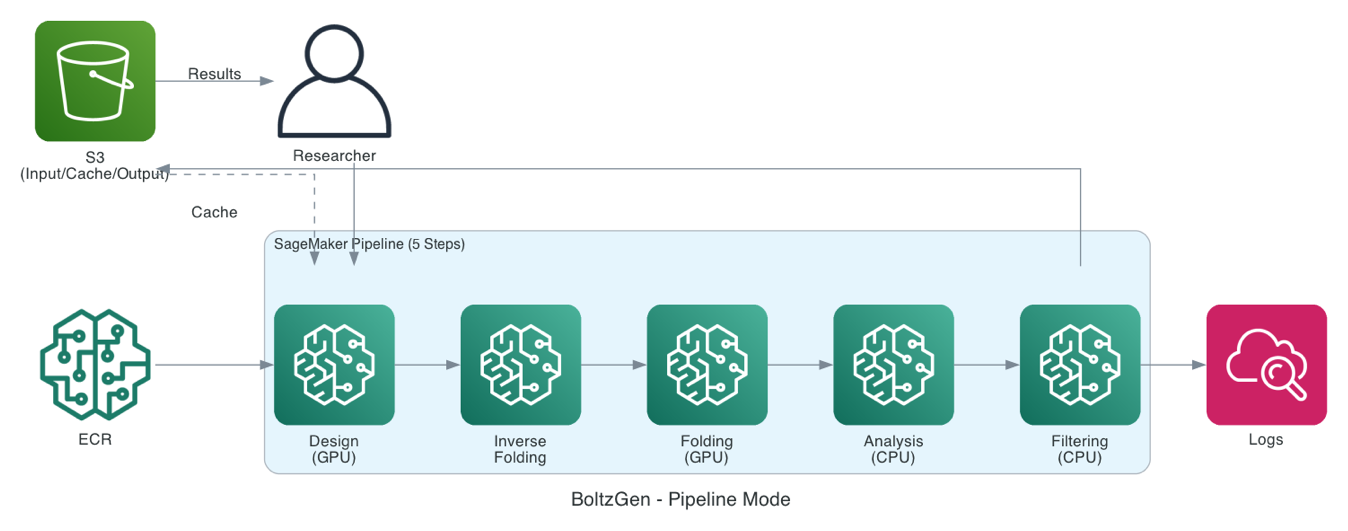
Выбор инстансов варьируется от ml.g4dn (T4 GPU, минимальная стоимость) до ml.g6e (NVIDIA L40S). Это позволяет подбирать инстанс под требуемый бюджет и пропускную способность. Решение ориентировано на академические лаборатории, биотехнологические стартапы, фармацевтические R&D-отделы и образовательные программы. Исходный код и скрипты развертывания доступны в репозитории GitHub.


