
Метод Retrieval Augmented Generation (RAG) улучшает ответы языковых моделей за счёт подгрузки внешних данных, но при вопросах, требующих связи информации из нескольких документов (multi-hop reasoning), стандартные подходы часто дают сбой. Каждый документ обрабатывается независимо, и модель не может легко соединить разрозненные факты.
HippoRAG, предложенный исследователями, решает эту проблему, копируя механизм человеческой памяти: неокортекс обрабатывает восприятие, а гиппокамп создаёт индекс ассоциаций. В программной реализации это выражается в построении графа знаний (Knowledge Graph) на основе извлечённых из текста триплетов «субъект-отношение-объект». Для поиска релевантных узлов графа используется алгоритм Personalized PageRank (PPR), который позволяет одним шагом пройти по нескольким связям, а не перебирать их итеративно.
| Компонент | Роль в HippoRAG |
|---|---|
| Amazon Bedrock | Извлечение триплетов, ответы на вопросы, распознавание сущностей |
| Amazon Neptune | Хранение графа знаний |
| Amazon Neptune Analytics | Выполнение Personalized PageRank |
| Amazon Titan Embeddings | Векторизация текста |
На практике HippoRAG развёрнут на стеке управляемых сервисов AWS. Amazon Bedrock предоставляет LLM для генерации триплетов, ответов на вопросы и распознавания именованных сущностей. Amazon Neptune служит графовой базой данных для хранения структуры знаний. Для выполнения сложных алгоритмов, включая PPR, используется Amazon Neptune Analytics. Векторные представления текста создаются с помощью Amazon Titan Embeddings. Весь процесс импорта данных из набора HotpotQA (JSON → триплеты → CSV → S3 → Neptune) автоматизирован классом HotpotQANeptuneImporter.
Для ранжирования релевантности применяется персонализированный PageRank, обеспечивающий одношаговый многозвенный поиск.
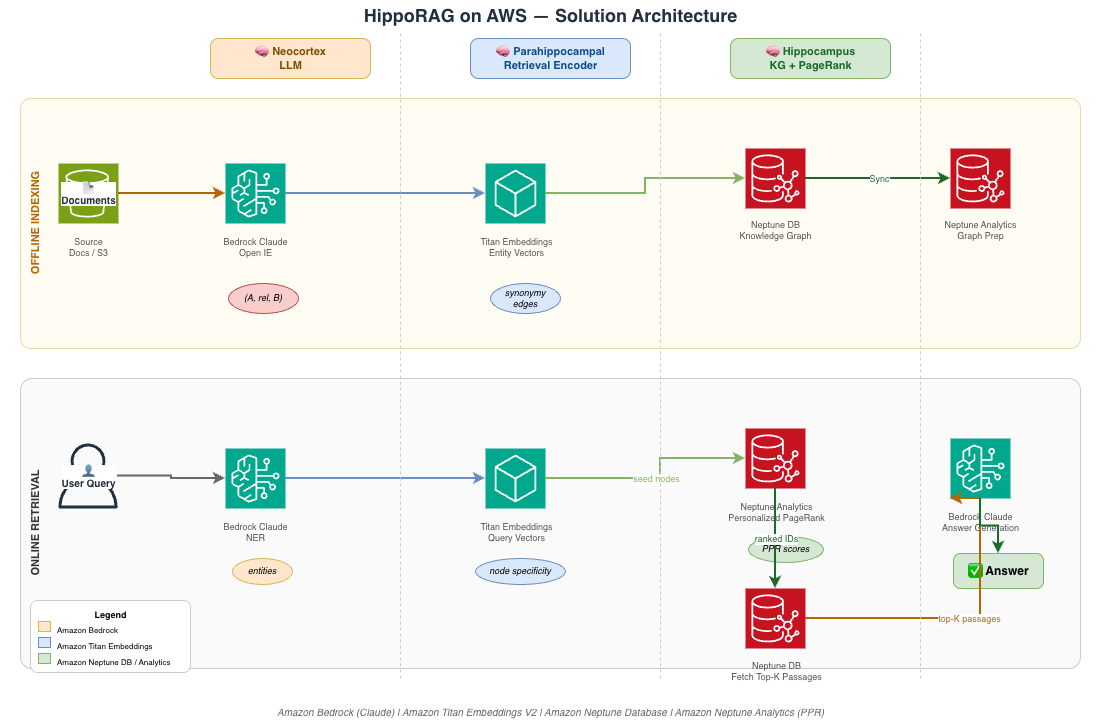
Подход HippoRAG особенно актуален для корпоративных сценариев, где ответы требуют объединения информации из множества источников, например, в юридических или медицинских системах. Замена стандартного RAG на вариант с графом знаний и персонализированным PageRank позволяет сократить количество итераций и улучшить точность при многозвенных запросах. Реализация на AWS упрощает масштабирование и интеграцию с существующей инфраструктурой.


