
Одна из типичных проблем при дообучении языковых моделей в корпоративной среде — разрыв между платформой обучения и системой управления данными. Если задание SageMaker ИИ Training читает объекты из S3 напрямую, минуя Databricks Unity Catalog, компания теряет информацию о том, какие данные использовались для обучения конкретной модели. В регулируемых отраслях — финансах, здравоохранении, страховании — это создаёт реальные compliance-риски.
AWS Machine Learning Blog опубликовал детальную архитектуру, закрывающую этот пробел. Решение объединяет три сервиса: Amazon SageMaker ИИ для оркестрации и обучения, Amazon EMR Serverless для предобработки данных на Apache Spark и Databricks Unity Catalog как единую точку управления метаданными, правами доступа и линией данных. Все учётные данные Databricks хранятся в AWS Secrets Manager и передаются через OAuth M2M (machine-to-machine) — протокол, выдающий короткоживущие токены для сервисных принципалов без хранения паролей в коде.
| Компонент | Роль в архитектуре |
|---|---|
| Amazon SageMaker AI Studio — JupyterLab | Оркестрация рабочего процесса и обучение модели |
| Amazon EMR Serverless | Предобработка данных на Spark без управления кластерами |
| Databricks Unity Catalog | Каталог метаданных, управление доступом и lineage |
| Hugging Face | Источник предобученной модели Ministral-3-3B-Instruct |
| Amazon S3 | Хранение данных и артефактов модели |
| AWS Secrets Manager | Управление OAuth-учётными данными Databricks |
Для демонстрации используются публичные данные SEC EDGAR — раздел «Факторы риска» из годовых (10-K) и квартальных (10-Q) отчётов компаний из индекса S&P 500 за 2023–2024 годы. Данные загружаются через публичный API SEC, извлекаются в JSON-формат и размещаются в S3-бакете с партиционированием по типу формы, фискальному году и идентификатору компании (CIK). На этих данных дообучается модель Ministral-3-3B-Instruct, полученная с Hugging Face.
Предобработка данных выполняется через EMR Serverless с Apache Spark без необходимости управлять кластерами вручную.
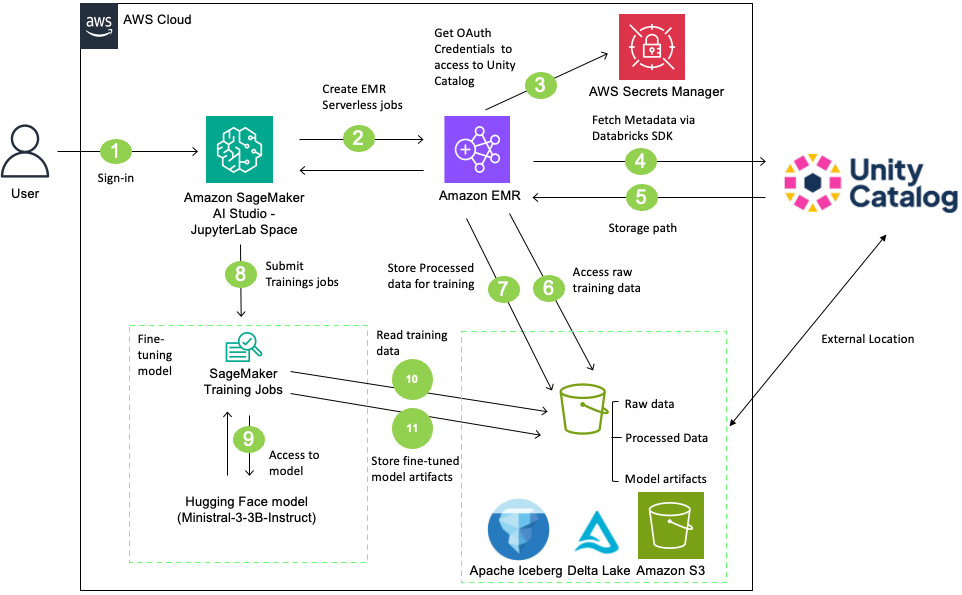
Поток данных выглядит следующим образом: пользователь запускает процесс из JupyterLab в SageMaker ИИ Studio, EMR Serverless-задание читает исходную таблицу Unity Catalog через Open REST API, обрабатывает данные Spark-ом и записывает результат в новую таблицу Unity Catalog. Затем SageMaker ИИ Training job забирает обработанные данные, дообучает модель и сохраняет артефакты обратно в S3-бакет, управляемый Unity Catalog. Финальный шаг — регистрация модели в Unity Catalog и создание записи о внешней линии данных, связывающей исходные таблицы с обученной моделью.
Ключевое отличие подхода от прямого доступа к S3 — все операции чтения и записи проходят через авторизационную модель Unity Catalog. Это означает, что политики доступа применяются консистентно, а в журнале аудита фиксируется полная цепочка: от исходных данных до зарегистрированного артефакта модели. Для команд, работающих под требованиями SOC 2, GDPR или отраслевых регуляторов, это принципиально — без такой трассировки невозможно ответить на вопрос регулятора о том, на каких данных обучалась модель, принявшая конкретное решение.
С технической точки зрения решение не требует отказа от существующей инфраструктуры: Databricks-воркспейс остаётся на AWS, данные физически хранятся в S3, а SageMaker ИИ и EMR Serverless работают в той же облачной среде. EMR Serverless снимает необходимость управлять Spark-кластерами вручную — ресурсы выделяются под конкретное задание и освобождаются после его завершения. Для запуска потребуется настроенный VPC с доступом в интернет, IAM-роли для SageMaker ИИ и EMR Serverless, а также OAuth-credentials для Databricks, созданные через сервисный принципал.


