
Ошибка распознавания символа в юридическом тексте — это правка в одном месте. Та же ошибка в финансовой таблице распространяется по связанным расчётам и искажает аналитику на нескольких уровнях. Именно эту проблему решает связка Pulse ИИ и Amazon Bedrock, описанная в блоге AWS Machine Learning Blog.
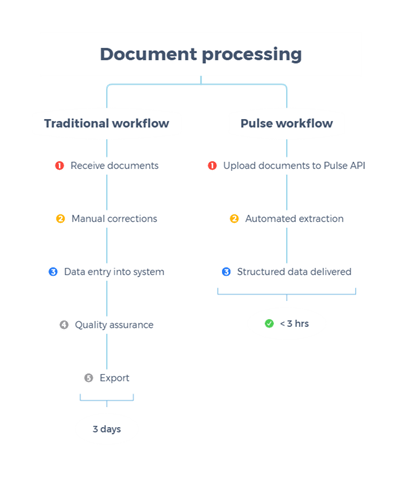
Финансовые документы — балансы, отчёты о прибылях и убытках, материалы SEC, аудиторские заключения — устроены иначе, чем обычные тексты. В них есть объединённые ячейки таблиц, многоколоночные макеты с перекрёстными ссылками и контекстно-зависимые данные, смысл которых нельзя понять без знания структуры документа. Классические OCR-системы обрабатывают страницу как изображение и не улавливают эти связи. Результат — каскад ручных исправлений и задержки в аналитическом процессе.
| Характеристика | Традиционный OCR | Pulse AI + Amazon Bedrock |
|---|---|---|
| Подход к документу | Обработка как изображения | Семантическое понимание структуры |
| Сложные таблицы | Ошибки при объединённых ячейках | Поддержка иерархических данных |
| Время обработки 1000 документов | Несколько дней | Менее трёх часов |
| Дообучение модели | Не предусмотрено | Supervised fine-tuning на Nova Micro |
| Инфраструктура | Требует ML-ops | Полностью управляемая через Bedrock |
Pulse ИИ подходит к задаче иначе: система объединяет vision language models с классическими ML-компонентами, специально настроенными под понимание документов. Это позволяет извлекать структурированные данные с семантическим контекстом, а не просто распознавать символы. В одном из задокументированных развёртываний пакет из примерно 1000 сложных финансовых документов был обработан менее чем за три часа — ранее на это уходило несколько дней. На выходе — структурированные, верифицируемые данные, готовые для аналитических систем и ИИ-приложений.
Pulse ИИ совмещает vision language models с классическими ML-компонентами для семантического понимания документов
Архитектура конвейера состоит из десяти шагов. Документы поступают в контейнер Pulse, развёрнутый в VPC клиента, или обрабатываются через SaaS-вариант сервиса. После извлечения данных результат конвертируется в формат supervised fine-tuning для Amazon Bedrock и сохраняется в S3. Затем запускается задача дообучения на модели Amazon Nova Micro (amazon.nova-micro-v1:0) — компактной модели с контекстным окном 128K токенов, оптимизированной для задач извлечения текста. После завершения обучения кастомная модель импортируется в Amazon Bedrock и разворачивается с Provisioned Throughput для стабильной производительности в продакшене.
Amazon Nova Micro — часть семейства Nova, которое AWS представила как набор моделей с высоким соотношением цены и качества. Для задач дообучения на корпоративных финансовых данных важно, что Bedrock берёт на себя всю инфраструктуру: не нужно планировать мощности или управлять ML-ops. Команда настраивает данные и бизнес-логику, платформа занимается остальным.
Среди клиентов Pulse — Samsung, Cloudera, Howard Hughes и финансовые институты из списка Fortune 500, а также крупные private equity-фирмы. Для воспроизведения описанного конвейера потребуются аккаунт AWS, настроенные IAM-политики для доступа Bedrock к S3, аккаунт Pulse Standard (регистрация на runpulse.com), Python 3.12 и EC2-инстанс типа t3.medium на Amazon Linux 2023 в регионе us-east-1. Авторы блога отдельно предупреждают: инстанс EC2, хранилище S3, задачи дообучения и Provisioned Throughput тарифицируются по факту использования, поэтому инстанс следует останавливать после завершения работы.


