
С ростом числа генеративных ИИ-приложений в промышленной эксплуатации вопросы отказоустойчивости инференса больших языковых моделей (LLM) выходят на первый план. В блоге AWS Machine Learning Blog описаны пять паттернов отказоустойчивости для инференса LLM на базе Amazon Bedrock — от использования встроенного кросс-регионального вывода до оркестрации через LLM-шлюз. Паттерны охватывают четыре ключевых измерения архитектуры: доступность, время ответа, стоимость и пропускную способность. Эти параметры взаимосвязаны: например, маршрутизация между регионами повышает доступность и пропускную способность, но может увеличить задержку.
Первый и базовый паттерн — Amazon Bedrock cross-Region inference (CRIS). Это нативная функция, которая автоматически направляет запросы из исходного региона в оптимальный на основе текущей доступности, задержки и нагрузки. CRIS позволяет увеличить совокупную пропускную способность, снизить риск исчерпания квот и сохранить данные в пределах географической зоны (например, только регионы США или ЕС). Для сценариев, допускающих бо́льшую задержку, доступны глобальные профили, маршрутизирующие запросы по всем коммерческим регионам. В демонстрационном примере при отправке 10 запросов к Amazon Bedrock через CRIS распределение оказалось следующим:
| Регион | Количество вызовов | Доля |
|---|---|---|
| us-east-1 | 1 | 10% |
| us-east-2 | 7 | 70% |
| us-west-2 | 2 | 20% |
| Регион | Количество вызовов | Доля | |--------|-------------------|------| | us-east-1 | 1 | 10% | | us-east-2 | 7 | 70% | | us-west-2 | 2 | 20% |
Первый паттерн — кросс-региональный вывод (CRIS) — автоматически распределяет запросы по регионам.
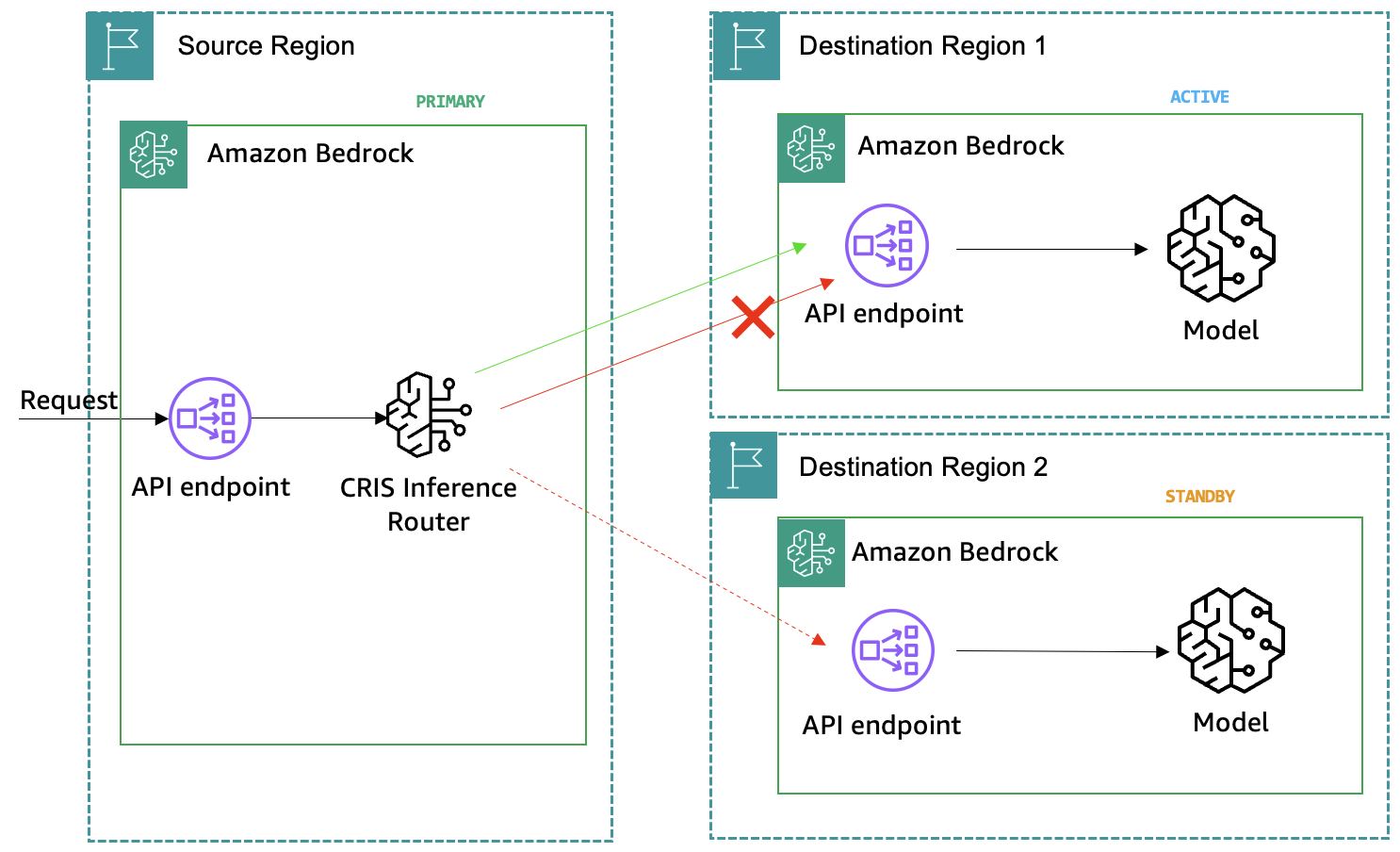
Остальные четыре паттерна развивают этот подход: от работы с квотами и изоляцией ресурсов до использования LLM-шлюза для мультимодельной оркестрации. Все примеры кода доступны в репозитории GitHub, что позволяет протестировать паттерны в собственной среде. Авторы предлагают поэтапный подход «crawl, walk, run» — внедрение паттернов по мере роста зрелости приложения. В будущем планируются публикации, посвящённые оптимизации времени ответа и стоимости. Важно: следование паттернам приводит к расходам на ресурсы AWS (Amazon Bedrock, CloudWatch). В репозитории приведены инструкции по очистке ресурсов.


