
Технические документы в аэрокосмической и автомобильной промышленности редко бывают чисто текстовыми. Рабочий наряд содержит фотографии сборочных шагов, инспекционный отчёт — рентгеновские снимки сварных швов, а сертификат на материал — S-N кривые усталости, которые инженер обязан проверить при проектировании. Традиционные поисковые системы обрабатывают такие документы через OCR: извлекают текст, индексируют строки и ищут по ним. Проблема в том, что OCR либо искажает, либо полностью теряет пространственный контекст: подпись на выносной линии поперечного разреза турбонасоса, цветовую шкалу тепловой карты или метки точек контроля качества на блок-схеме процесса.
Amazon Nova Multimodal Embeddings решает эту задачу иначе: вместо конвертации изображения в текст модель обрабатывает его напрямую и помещает результат в то же векторное пространство, что и текстовые эмбеддинги. Это означает, что косинусное сходство можно вычислять между текстовым запросом и изображением без промежуточных преобразований. Модель поддерживает четыре размерности эмбеддингов — 256, 384, 1024 и 3072. Для страниц с таблицами, графиками и аннотированными схемами предусмотрен специальный режим обработки DOCUMENT_IMAGE. Асимметричная схема эмбеддинга разделяет назначение векторов: GENERIC_INDEX — для индексируемых документов, GENERIC_RETRIEVAL — для поисковых запросов, что улучшает качество поиска без ручной настройки формата запросов.
| Конвейер | Метод обработки изображений | Хранилище векторов | Модель генерации |
|---|---|---|---|
| Pipeline A (мультимодальный) | Прямое эмбеддирование через Amazon Nova Multimodal Embeddings | Amazon S3 Vectors | Amazon Nova 2 Lite |
| Pipeline B (текстовый baseline) | OCR через Amazon Nova 2 Lite → текстовый эмбеддинг | Amazon S3 Vectors | Amazon Nova 2 Lite |
Для сравнения подходов команда AWS построила два параллельных конвейера на одном датасете. Датасет включал 15 отдельных технических изображений (CAD-схемы, инспекционные отчёты, графики испытаний, спецификации материалов, блок-схемы процессов) и пять многостраничных PDF (инструкции по сборке, отчёты об огневых испытаниях, уведомления об инженерных изменениях, сертификаты материалов, отчёты о несоответствиях). Все документы содержат синтетические аэрокосмические производственные данные. Конвейер A (мультимодальный) эмбеддировал каждое изображение и каждую страницу PDF напрямую через Amazon Nova Multimodal Embeddings и загружал векторы в индекс Amazon S3 Vectors. Конвейер B (текстовый baseline) сначала прогонял те же материалы через Amazon Nova 2 Lite для OCR-извлечения текста, затем эмбеддировал полученные строки и помещал их в отдельный индекс S3 Vectors.
Поддерживаются размерности эмбеддингов 256, 384, 1024 и 3072; в эксперименте использовались 1024 измерения как баланс качества и стоимости.
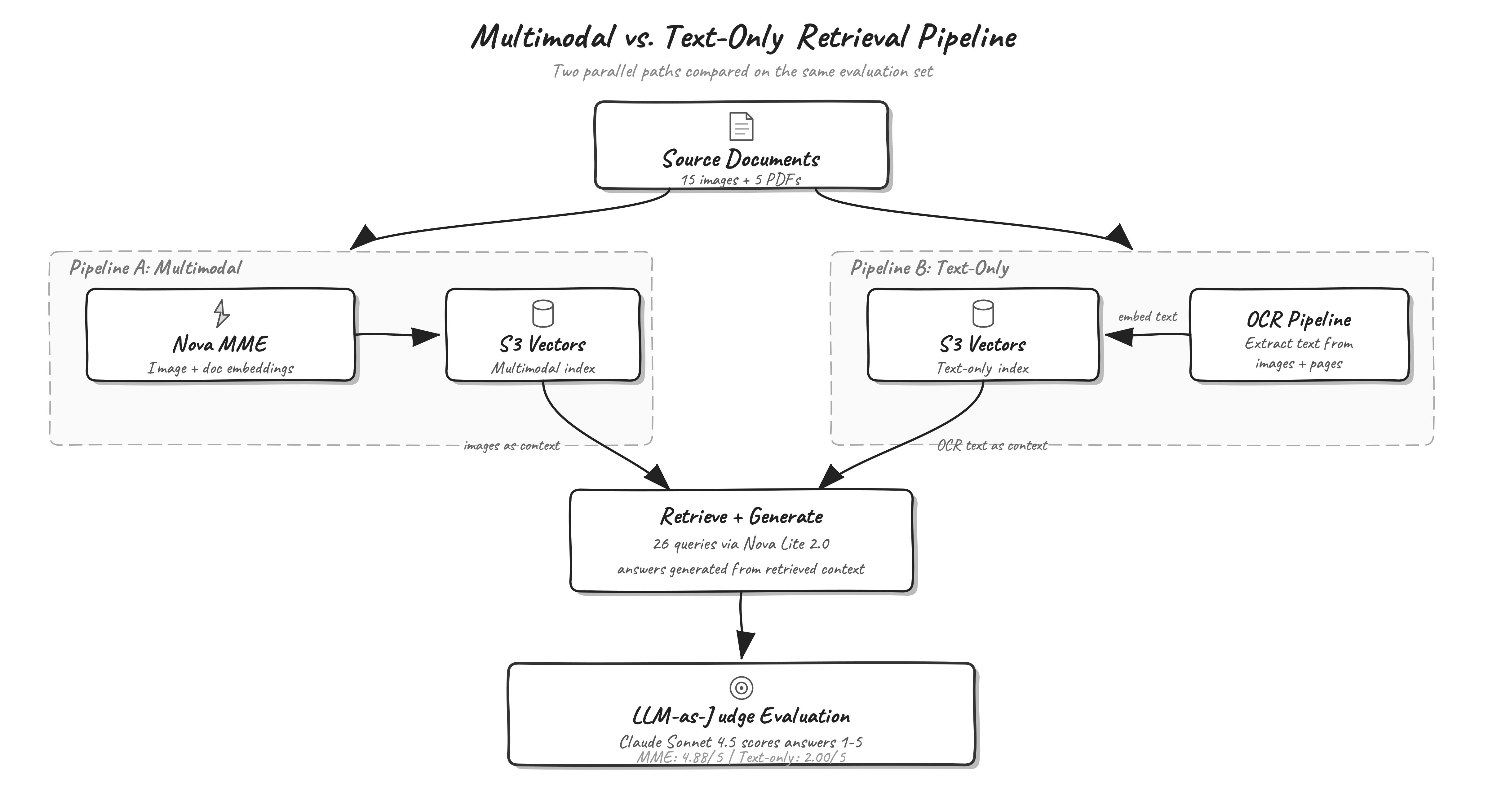
Оценка проводилась на 26 производственных запросах. Для мультимодального индекса измерялись метрики поиска: Recall@K, Mean Reciprocal Rank (MRR) и NDCG@K. Для обоих конвейеров контекст из индекса передавался в Amazon Nova 2 Lite для генерации ответа, после чего LLM-судья сравнивал ответ с эталоном. Такой подход позволяет оценить не только точность поиска, но и итоговое качество ответа — именно то, что важно конечному пользователю.
Подобные системы актуальны не только для аэрокосмоса. Любое производство, где документация содержит схемы, графики или фотографии — от фармацевтики до энергетики, — сталкивается с той же проблемой: текстовый поиск не видит визуальную информацию. Конкурирующие подходы, например GPT-4o Vision или открытые мультимодальные модели вроде LLaVA, тоже умеют работать с изображениями, однако Amazon Nova Multimodal Embeddings ориентирована именно на задачу retrieval: единое векторное пространство и асимметричные режимы индексирования и поиска — это архитектурное решение, заточенное под RAG-конвейеры, а не под генерацию описаний изображений. Полный код реализации опубликован в сопроводительном ноутбуке на GitHub.


