
Большинство поисковых API отдают HTML-страницы и короткие сниппеты, оптимизированные под браузер человека. Для ИИ-агента это означает дополнительный слой работы: нужны парсеры, краулеры и логика ранжирования, прежде чем контент попадёт в контекстное окно модели. Именно этот разрыв закрывает интеграция Exa в Strands Agents SDK.
Strands Agents — open-source фреймворк AWS, построенный на model-driven подходе. Разработчик задаёт модель, системный промпт и список инструментов, а дальше модель сама решает, какой инструмент вызвать, в каком порядке и когда остановиться. Агентный цикл на каждой итерации получает полную историю диалога, включая все предыдущие вызовы инструментов и их результаты. Это накопление контекста позволяет решать многошаговые задачи, недоступные одиночному вызову LLM. SDK поставляется с более чем 40 встроенными инструментами — файловые операции, выполнение кода, работа с AWS API, управление памятью — и поддерживает Model Context Protocol (MCP).
| Режим | Время отклика | Назначение |
|---|---|---|
| Instant | ~200 мс | Автодополнение, голосовые агенты, живые подсказки |
| Fast | ~450 мс | Агентные сценарии с десятками поисковых запросов |
| Auto (рекомендуется) | ~1 с | Большинство задач: баланс скорости и качества |
| Deep | ~3–6 с | Исследовательские задачи, где важна полнота охвата |
Exa — поисковый движок, изначально спроектированный для LLM и ИИ-агентов. В отличие от традиционных поисковиков, он работает на семантическом сходстве: запрос «стартапы в области климатических решений» вернёт релевантные компании, даже если на их страницах нет этой точной фразы. Результаты приходят очищенными от рекламы и SEO-шума, готовыми к прямой подаче в контекстное окно модели.
Exa — поисковый движок для LLM, работающий на семантическом сходстве, а не по ключевым словам; результаты приходят без рекламы и SEO-шума.
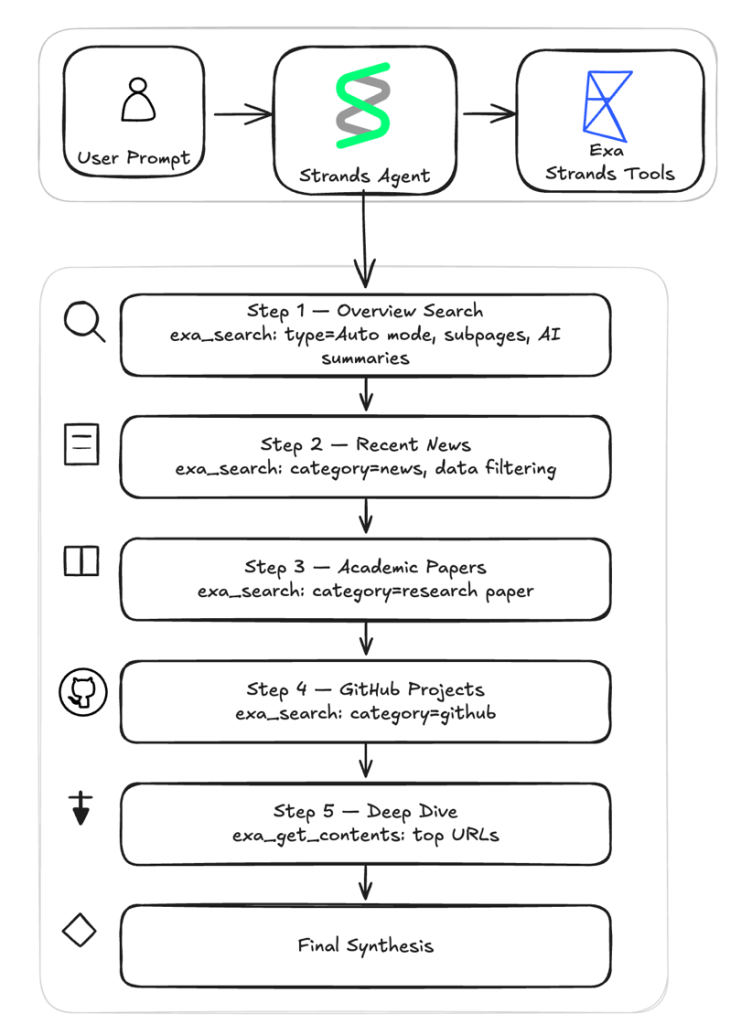
Интеграция добавляет два инструмента. Первый — exa_search — выполняет семантический поиск в четырёх режимах: Instant (~200 мс) для голосовых агентов и автодополнения, Fast (~450 мс) для агентных сценариев с десятками запросов, Auto (~1 с, рекомендуемый по умолчанию) и Deep (~3–6 с) для исследовательских задач, где важна полнота охвата. Поиск можно фильтровать по категориям контента — новости, научные статьи, GitHub-репозитории, PDF, финансовые отчёты, профили людей — а также по домену и дате. В одном вызове агент может запросить и результаты, и синтезированное резюме по каждому из них.
Второй инструмент — exa_get_contents — извлекает полный текст страниц по списку URL. Exa поддерживает кэш уже обходённых страниц, что ускоряет повторные запросы. Если страница не закэширована или нужна свежая версия, инструмент автоматически переключается на живой краулинг с настраиваемым таймаутом. Объём возвращаемого текста тоже регулируется: например, можно ограничить вывод пятью тысячами символов.
Подключение не требует отдельного SDK Exa — интеграция работает напрямую через REST API. Достаточно установить пакет strands-agents-tools, импортировать инструменты и передать их в параметр tools= конструктора Agent. Модель сама обучается использовать их по сигнатурам функций. Для работы нужны Python 3.10+, доступ к Amazon Bedrock и API-ключ Exa.
Подобный подход — встраивание специализированного поискового слоя прямо в агентный фреймворк — отражает более широкую тенденцию в отрасли. Разработчики агентов для ресёрча, фактчекинга и конкурентной разведки сталкиваются с одной и той же проблемой: общедоступные поисковые API не проектировались под машинное потребление. Решения вроде интеграции Exa пытаются убрать этот слой трансформации, делая веб-поиск таким же нативным инструментом агента, как вызов файловой системы или исполнение кода.


