
Инженерная организация Miro насчитывает около 100 команд, каждая из которых отвечает за отдельный продуктовый домен. Когда баг попадал не в ту команду, начиналась цепочка переназначений: разработчики тратили время на изучение чужого контекста, SLA нарушались, а пользователи ждали. По оценке самой компании, суммарные потери от этой проблемы составляли 42 года рабочего времени ежегодно.
Предыдущая система маршрутизации строилась на дообученной модели GPT. Её слабое место — статичность: при слиянии команд, появлении новых продуктов или изменении зон ответственности модель требовала переобучения на размеченных данных. Таких данных для новых структур зачастую просто не существовало, и точность классификации быстро падала. Схожая проблема характерна для любых fine-tuned классификаторов — BERT и его производных: они плохо справляются с динамичными организационными изменениями.
| Метрика | До BugManager | После BugManager |
|---|---|---|
| Количество переназначений между командами | базовый уровень | в 6 раз меньше |
| Time-to-resolution | несколько дней | в 5 раз быстрее (часы) |
| Потери от неверной маршрутизации | ~42 года рабочего времени/год | существенно снижены |
Вместе с командой AWS PACE (Prototyping and Cloud Engineering) Miro разработала BugManager — систему, которая не требует переобучения. В её основе лежит подход RAG (Retrieval Augmented Generation): вместо того чтобы «запоминать» знания о командах в весах модели, система каждый раз извлекает актуальный контекст из базы знаний. Источниками служат ранее закрытые тикеты Jira, pull request'ы из GitHub, документация Confluence и README-файлы репозиториев. Это позволяет системе адаптироваться к изменениям в структуре компании без какого-либо дополнительного обучения.
Время решения инцидентов сократилось в 5 раз — с нескольких дней до нескольких часов.
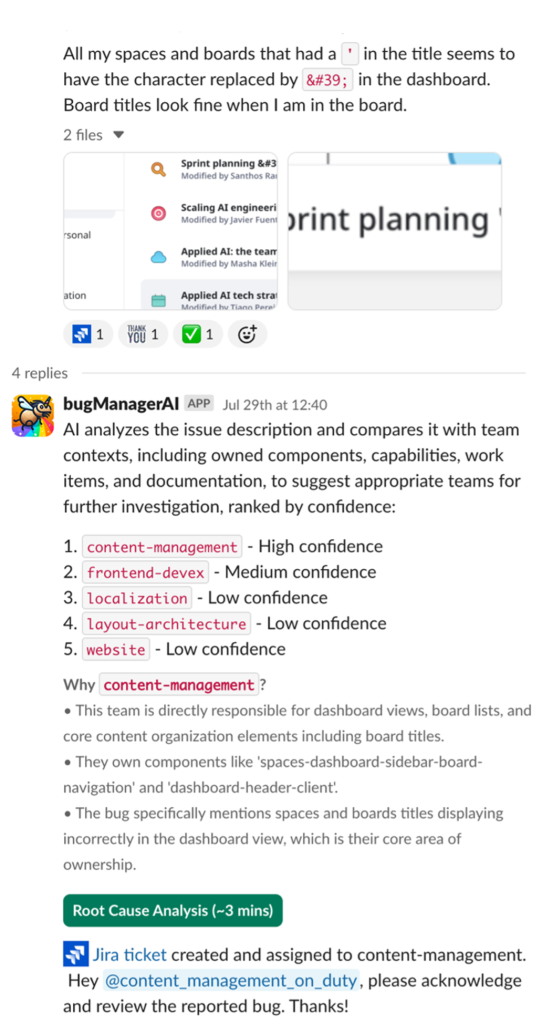
Рабочий процесс BugManager начинается в Slack: инженер публикует описание бага в выделенном канале. Если к сообщению прикреплены скриншоты или видеозаписи экрана, система передаёт их в Amazon Nova Pro — мультимодальную модель, которая преобразует визуальный контент в текст. Чтобы извлечённое описание было специфичным, а не абстрактным, перед парсингом система уже делает RAG-запрос по тексту бага и подгружает документацию о конкретной функции продукта, изображённой на скриншоте.
Полученный текст обогащается контекстом из нескольких баз знаний через Amazon Bedrock Knowledge Bases, после чего Claude Sonnet 4 формирует итоговый промпт для классификации. На выходе — список до пяти команд-кандидатов с обоснованием выбора. По умолчанию баг назначается на первую команду, но инженер может скорректировать выбор вручную. Опционально система генерирует анализ первопричины, обращаясь к исходному коду репозиториев Miro.
Вся система работает как Python-микросервис в кластере Amazon EKS. Интеграция через Slack снизила порог входа для инженеров: не нужно переходить в отдельный интерфейс или осваивать новый инструмент. Результат — шестикратное снижение числа переназначений и пятикратное ускорение time-to-resolution. Подход демонстрирует, что для задач с высокой динамикой данных RAG-архитектура может быть практичнее дообученных классификаторов даже при большом числе классов.


