
Одна из хронических проблем обучения языковых моделей с подкреплением — так называемый reward hacking: модель находит способы максимизировать числовую оценку, не решая задачу по существу. Если функция вознаграждения неточна или содержит скрытые стимулы, модель учится обходить критерии, а не выполнять их. AWS Machine Learning Blog опубликовал подробное руководство, в котором предлагает комбинацию двух техник — RLVR и GRPO — для устранения этой проблемы при обучении на SageMaker AI.
RLVR (Reinforcement Learning with Verifiable Rewards) строится на программных функциях вознаграждения: вместо того чтобы собирать оценки людей, система автоматически проверяет ответ модели по объективным правилам. Это особенно эффективно там, где результат можно однозначно верифицировать — математические вычисления, генерация кода, символьные преобразования. Такой подход снимает узкое место в виде разметки и позволяет быстро итерировать при изменении требований к задаче.
| Техника | Роль в обучении | Ключевое преимущество |
|---|---|---|
| RLVR | Программная верификация правильности ответа | Устраняет reward hacking, не требует разметки людьми |
| GRPO | Сравнение кандидатов внутри группы промптов | Снижает дисперсию градиентов, ускоряет сходимость |
| Few-shot (8 shots) | Шаблоны правильных ответов в промпте | Сужает пространство поиска, задаёт нужный формат |
GRPO (Group Relative Policy Optimization) — алгоритм оптимизации политики, который оценивает качество ответов не глобально, а внутри групп. На каждый промпт модель генерирует несколько кандидатов, после чего алгоритм сравнивает их между собой и обновляет веса относительно группового базового уровня. Это снижает дисперсию градиентов и ускоряет сходимость по сравнению с классическими методами вроде PPO, где оценка идёт по всему батчу сразу. GRPO был предложен командой DeepSeek и получил широкое распространение после успеха модели DeepSeek-R1 в начале 2025 года.
GRPO сравнивает качество ответов внутри групп, а не по всему датасету сразу — это снижает дисперсию обучения и ускоряет сходимость.
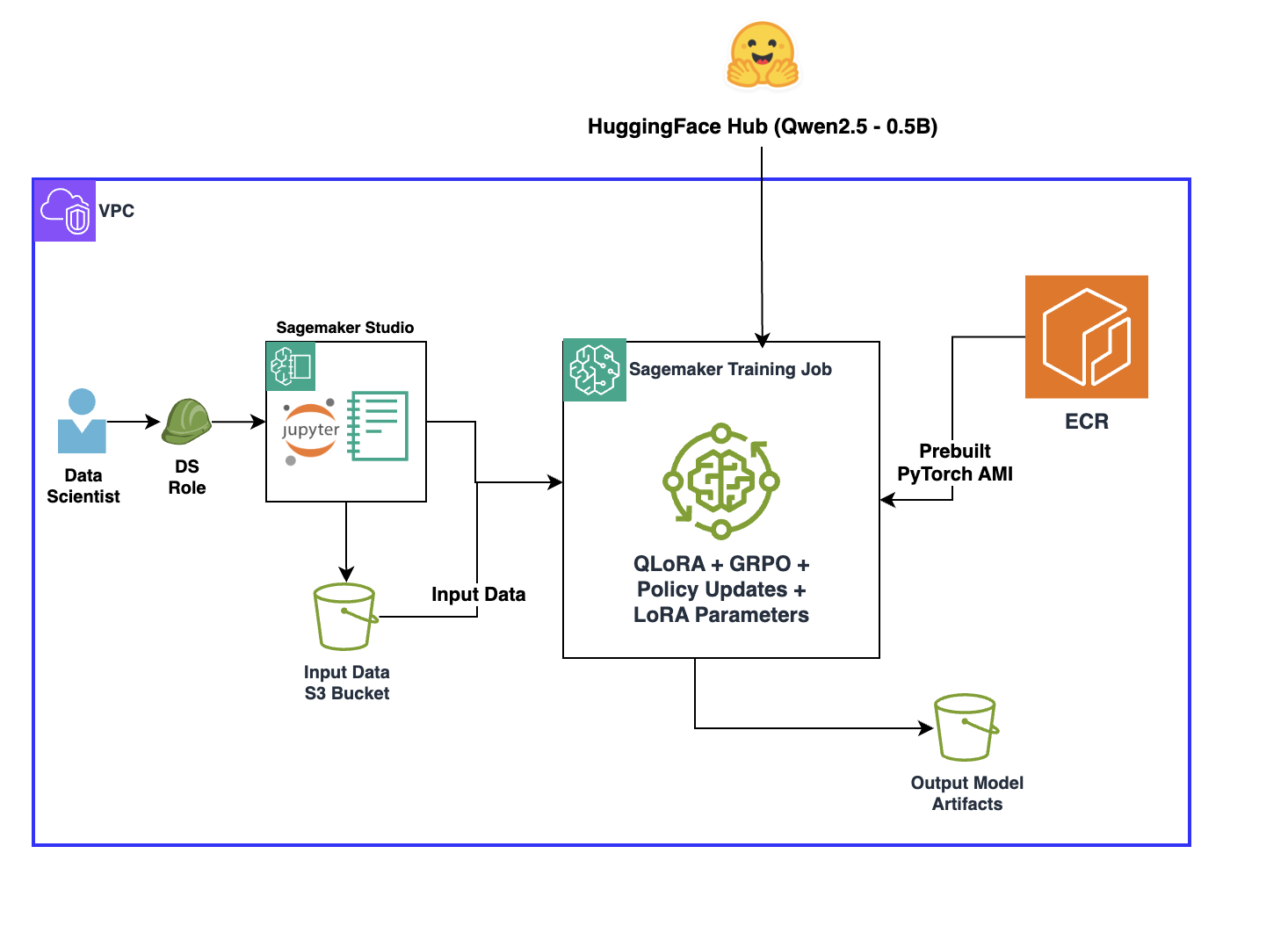
В качестве тестового датасета используется GSM8K — сборник из 7 473 школьных математических задач с пошаговыми решениями. Перед обучением из каждого примера извлекается финальный ответ: именно он служит эталоном для функции вознаграждения. Дополнительно к каждому промпту добавляются 8 few-shot примеров — готовых образцов правильно оформленных решений. Это сужает пространство поиска для модели: вместо того чтобы угадывать формат ответа, она видит конкретные шаблоны и исследует вариации вокруг них.
Обучение запускается на модели Qwen2.5-0.5B через SageMaker Training Jobs на инстансе ml.p4d.24xlarge — восьмикарточная конфигурация на базе NVIDIA A100. AWS подчёркивает, что для задач генерации кода потребуется более крупная модель, например Qwen2.5-Coder-7B, и соответственно более мощный инстанс. SageMaker Training Jobs автоматически завершает работу кластера после окончания обучения, что исключает лишние расходы на простаивающие GPU.
Весь код доступен в репозитории aws-samples/amazon-sagemaker-generativeai на GitHub. Ноутбук model-finetuning-grpo-rlvr.ipynb рассчитан на Python 3.12 и запускается из JupyterLab-пространства в SageMaker Studio на инстансе ml.t3.medium — тяжёлые вычисления выполняются на отдельном эфемерном тренировочном инстансе, а не на ноутбучном сервере.


