Исследователи DeepMind сформулировали проблему, с которой сталкивается каждый пользователь ИИ-инструментов: чтобы получить помощь, нужно перетащить свой мир в окно чата — скопировать текст, сделать скриншот, объяснить, что именно на нём важно. Adrien Baranes и Rob Marchant предлагают перевернуть эту логику: пусть модель сама считывает контекст там, где находится пользователь.
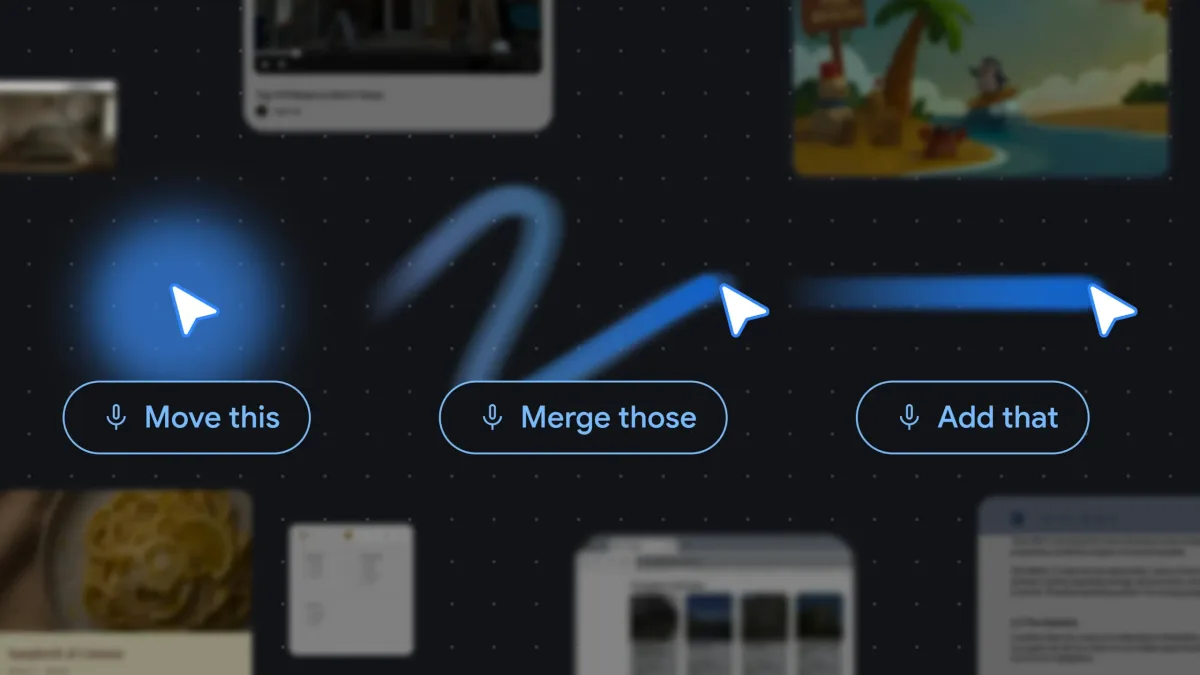
Концепция получила название Pointer Engineering. Её суть — сделать курсор мыши главной переменной при передаче контекста модели. Gemini отслеживает, на что именно указывает курсор, анализирует визуальное окружение и семантику объекта, после чего пользователь может отдать короткую команду: «Fix this», «Move that here», «Book it». Никакого развёрнутого описания не требуется — модель сама понимает, что такое «это» и «туда».
В основе подхода лежит идея преобразования пикселей в «структурированные сущности»: адреса, даты, объекты, фрагменты текста. Рукописная заметка в поле зрения курсора превращается в интерактивный список задач; стоп-кадр из видео — в ссылку на бронирование того места, которое на нём изображено. Речь идёт не о распознавании текста в классическом смысле, а о том, чтобы модель понимала смысловую роль элемента в текущем контексте пользователя.
Модель Gemini анализирует визуальный и семантический контекст вокруг курсора, превращая пиксели в структурированные сущности.
Часть принципов Pointer Engineering уже реализована в Gemini для Chrome: там можно выделить фрагмент веб-страницы и задать вопрос напрямую, без копирования в отдельный чат. На готовящемся устройстве Googlebook функция появится под коммерческим названием Magic Pointer.
Авторы честно обозначают границы подхода: он оптимизирован для коротких, разговорных взаимодействий — тех случаев, когда пользователь хочет быстро что-то поправить или переместить. Сложные задачи, требующие точной постановки условий, по-прежнему нуждаются в развёрнутых промптах. Pointer Engineering не конкурирует с prompt engineering — он закрывает другой сценарий.
Для отрасли это направление интересно тем, что смещает фокус с качества формулировки на качество указания. Сейчас конкурирующие решения используют скриншоты или нарисованные от руки маркеры — например, красные стрелки в видеоредакторах — как визуальные якоря для детальных промптов. Подход DeepMind пытается убрать даже этот промежуточный шаг, сделав курсор достаточным носителем намерения. Если концепция получит широкое распространение, это может изменить то, как проектируются интерфейсы ИИ-ассистентов: вместо текстового поля ввода — пространство экрана как основная поверхность взаимодействия.


